





























21/01/2010
Arithmétique des polynomes: Bézout et applications
On considère les polynômes à une variable à coefficients dans ![]() ou
ou ![]() ou
ou ![]() . Les algorithmes de base déjà évoqués sont l'évaluation en un point (méthode de Horner), l'addition, la soustraction, la multiplication et la division euclidienne de A par B
. Les algorithmes de base déjà évoqués sont l'évaluation en un point (méthode de Horner), l'addition, la soustraction, la multiplication et la division euclidienne de A par B ![]() 0 :
0 :
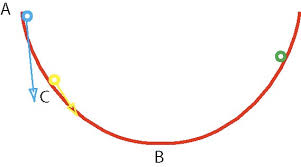
A l'aide de la division euclidienne, on peut calculer le PGCD de deux polynômes par l'algorithme d'Euclide. Nous allons présenter l'algorithme d'Euclide étendu (ou de Bézout)
Algorithme :
On construit en fait 3 suites (Un), (Vn) et (Rn) telles que :
- on initialise U0 = 1, V0 = 0, R0 = A et U1 = 0, V1 = 1, R1 = B
- on calcule les indices n + 2 en fonction de n et n + 1 en effectuant la division euclidienne de Rn par Rn+1 Rn = QnRn+1 + Rn+2, Un+2 = Un - QnUn+1, Vn+2 = Vn - QnVn+1
- on s'arrête au dernier reste non nul
Exemple :
A = x3 -1, B = x2 + 1, les rangs 0 et 1 sont donnés ci-dessus. Au rang 2, Q0 est le quotient euclidien de A par B (fonction quo) donc x, d'où
Puis on divise x2 + 1 par - x - 1, quotient - x + 1, donc
Preuve de l'algorithme :
On montre facilement par récurrence que la relation AUn + BVn = Rn est conservée. Comme Rn est la suite des restes, le dernier reste non nul est bien le pgcd de A et B. D'autre part, examinons les degrés des Vk. Supposons que deg(A) ![]() deg(B) (sinon on échange A et B). Au rang n = 0, V0 = 0 donc V2 = - Q0V1, aux rangs suivants le degré de Qn est non nul (car le degré de Rn+1 est strictement inférieur au degré de Rn) On montre donc par récurrence que la suite des degrés de Vn est croissante et que :
deg(B) (sinon on échange A et B). Au rang n = 0, V0 = 0 donc V2 = - Q0V1, aux rangs suivants le degré de Qn est non nul (car le degré de Rn+1 est strictement inférieur au degré de Rn) On montre donc par récurrence que la suite des degrés de Vn est croissante et que :
Comme deg(Qn)=deg(Rn)-deg(Rn+1), on en déduit que
Donc si n + 2 est le rang du dernier reste non nul, Vn+2 = V et degV=degA-degRn+1 est donc strictement inférieur au degré de A (car Rn+1, l'avant-dernier reste non nul, est de degré plus grand ou égal à 1). On en déduit enfin que le degré de U est strictement inférieur au degré de B, car AU = R - BV, le degré de BV est strictement inférieur à celui de B plus celui de A.
L'identité de Bézout permet de résoudre plus générallement une équation du type
où A, B, C sont trois polynômes donnés, à condition que C soit divisible par le pgcd de A et B. L'ensemble des solutions s'obtient à partir d'une solution particulière U, V de Bézout, notons c = C/gcd(A, B), on a alors
et l'ensemble des solutions est donné par u = cU - PB, v = cV + PA où P est un polynôme quelconque. Si le degré de C est plus petit que le degré de A plus le degré de B, il existe une solution ``priviligiée'', on prend pour u le reste de la division euclidienne de cU par B, v est alors le reste de la division euclidienne de cV par A pour des raisons de degré.
Exemple : si on veut résoudre
on multiplie U = x - 1 et V = 1 + x - x2 par x2 ce qui donne une solution
l'ensemble des solutions est de la forme
et la solution priviligiée (de degrés minimaux) est
L'identité de Bézout intervient dans de nombreux problèmes en particulier la décomposition en éléments simples d'une fraction rationnelle. Si le dénominateur D d'une fraction se factorise en produit de 2 facteurs D = AB premiers entre eux, alors il existe deux polynômes u et v tels que N = Au + Bv, donc
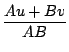 =
=
Si de plus N/D est une fraction propre (degré de N plus petit que celui de D), alors u/B et v/A sont encore des fractions propres (en calculant le reste de la division euclidienne pour u et v comme expliqué ci-dessus).
Par exemple :
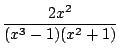 =
= 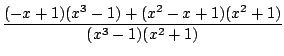 =
= 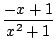 +
+ 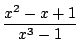
Les applications sont diverses, citons
- le calcul de primitive de fraction rationnelles (et tout ce qui s'y ramène), par exemple
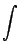 = = +
= = +
Puis on fait apparaitre la dérivée du dénominateur au numérateur pour éliminer les x, 2x = (x2 + 1)'
= - 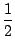
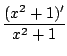 +
+ 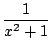 +
+ = - ln(x2 +1) + arctan(x) +
pour faire le calcul complet, il faut aussi décomposer la fraction restante (exercice!) - le calcul de transformée de Laplace inverse de fractions rationnelles, l'idée est la même, sauf qu'on remplace l'intégrale par la transformée de Laplace inverse (et les formules donnant la transformée inverse de 1/(x - p), 1/(x2 + p2), p/(x2 + p2) respectivement exp(px), sin(xp)/p, cos(px)) (calcul non exigible à l'examen)
- le calcul du terme d'ordre n du développement de Taylor en 0 d'une fraction rationnelle. On décompose, et on se ramène à des séries dont le terme général est connu, comme (a + x)-n. Par exemple pour connaitre le développement de 1/(x2 - 3x + 2), on factorise le dénominateur 1/((x - 1)(x - 2)), on décompose
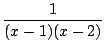 =
= 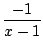 +
+ 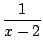 =
= 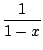 -
- 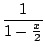
et on développe, le terme d'ordre n est donc 1 - (1/2)n+1.
Il faut néanmoins savoir factoriser un polynôme, ce dont nous parlerons dans la section suivante.
Exercice : Calculer l'intégrale
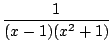
en utilisant l'identité de Bézout pour décomposer la fraction rationnelle. Trouver à l'aide de cette décomposition le terme d'ordre n du développement de Taylor de la fraction à intégrer, vérifier avec un logiciel de calcul formel que les termes d'ordre 0 à 3 sont corrects.
Una autre application est l'élimination dans les systèmes polynomiaux, par exemple considérons le système de 2 équations à 2 inconnues (intersection d'une ellipse et d'un cercle) :
En calculant les coefficients de Bézout des 2 polynômes en x x2 + y2 - 9 et x2 +2y2 - 2xy - 7 et en multipliant au besoin par le PPCM (plus grand commun multiple) des dénominateurs, on obtient à droite de l'équation de Bézout un polynôme ne dépendant que de y et qui s'annule aussi aux solutions du système, on peut alors résoudre en y (en factorisant) puis en x. Ici par exemple ce polynome est 5y4 -32y2 + 4. Cette méthode se systématise, le polynome obtenu par élimination d'une variable est appelé résultant.
Retour à la page principale de mat249 Source : http://www-fourier.ujf-grenoble.fr/~parisse/mat249/mat249...
06:50 Publié dans Arithmétique des polynomes: Bézout et applications | Lien permanent | Commentaires (0) | Tags : arithmétique des polynomes: bézout et applications |  |
|  del.icio.us |
del.icio.us |  |
|  Digg |
Digg |  Facebook
Facebook
08/01/2010
Entre figures et espaces : le cas des diagrammes en géométrie finie
Entre figures et espaces : le cas des diagrammes en géométrie finie

Le 12 novembre 2009, par Sébastien Gandon
Que représente une figure ? On cherche ici à montrer que la réponse à cette question n’est pas aussi simple qu’il y paraît. Nous sommes tous plus ou moins familiers avec les diagrammes de la géométrie classique, qui matérialisent une figure dans le plan ou dans l’espace. On sait peut-être moins que dans l’Antiquité, ces figures ... n’étaient dans rien. Ce n’est que bien plus tard, voici en gros un siècle, qu’on les a approchées comme partie d’un espace, espace vers lequel s’était déplacé une grande partie de l’effort mathématique. Ce qui est encore moins connu, c’est la manière dont des diagrammes semblables à ceux de la géométrie classique ont été utilisés, au début du XXe siècle, pour représenter ... des espaces. Il fallait pour cela que les mathématiciens s’intéressent aux géométries finies. Cet article est consacré à leur émergence et au rôle conceptuel qu’elles jouèrent dans l’histoire de la géométrie.
Introduction
EN histoire de la géométrie, on a souvent coutume d’opposer la géométrie qu’on dit « classique » —celle qui aurait été pratiquée depuis les Eléments d’Euclide jusqu’aux Fondements de la géométrie de Hilbert [1], publiés en 1899, et qui porte sur les propriétés des figures— à la géométrie dite « moderne » —celle qu’auraient inauguré les mêmes Fondements— et qui étudie les propriétés d’un espace. Dans cette perspective, les Éléments d’Euclide représentent le modèle d’une « géométrie des figures ». Certes, chez Euclide, les théorèmes sur le triangle, le cercle, etc. sont déduits, comme cela se passe chez Hilbert, à partir d’axiomes (les cinq « demandes » du livre I [2]). Mais on a mis en évidence depuis longtemps que les preuves euclidiennes comportaient des lacunes : certaines hypothèses, nécessaires dans les déductions, sont introduites par référence aux diagrammes et ne font l’objet ni d’axiomes, ni de propositions déduites de ces axiomes [3]. Les propriétés de l’espace dans lequel « vivent » et s’insèrent les figures étudiées ne sont ainsi complètement explicitées ni chez Euclide ni chez ses successeurs. En fait, cet « espace » n’est même abordé qu’indirectement, par le biais du fait que chaque figure peut être « enrichie » de diverses manières (les droites peuvent être prolongées, de nouveaux points introduits, etc.). Se permettre d’opérer de la sorte sur une figure, c’est dire qu’elle se trouve donc d’une certaine manière intrinsèquement liée à un « environnement », un plan par exemple. Mais Euclide n’élucide pas complètement les modalités de cette articulation. Ainsi, pour ne citer qu’un exemple, le simple fait que deux cercles « entrelacés » se coupent en deux points n’est prouvé nulle part !
C’est précisément sur ce point que la géométrie inaugurée par Hilbert se démarque des pratiques anciennes et c’est la raison pour laquelle on la qualifie de « moderne » : dans cette nouvelle manière de faire, la structure globale de l’espace est complètement donnée par un système d’axiomes. Tout ce qui peut être déduit des postulats est considéré comme un théorème, mais l’on s’interdit en revanche d’utiliser, dans les démonstrations, une information qui ne figurerait pas dans les axiomes ou qui ne pourrait pas être établie à partir d’eux. Hilbert a présenté dans les Fondements une liste de vingt postulats, répartis en cinq groupes [4], et l’ensemble des théorèmes de la géométrie d’Euclide s’en déduisent. À la différence des géomètres « classiques », au sens que nous avons introduit plus haut, Hilbert démontre ainsi, par exemple, le fait que deux cercles « entrelacés » se coupent en deux points. Ce trait trahit en fait une mutation fondamentale par rapport aux pratiques antérieures. Le géomètre hilbertien n’étudie plus tant les propriétés des figures qu’il ne s’intéresse à la structure des « modèles » du système axiomatique considéré. Un modèle, ici, c’est un ensemble d’objets (qu’on appelle « points », « droites ») et de relations (« être sur », « se couper », « être parallèle », etc.) qui satisfont tous les axiomes. Les points et les droites dans le plan, tels que les concevaient les mathématiciens grecs, obéissent à tous les postulats de Hilbert. Mais il en va de même des couples de nombres réels (l’interprétation de « points » dans la géométrie « cartésienne ») et des équations linéaires en
Dans cette nouvelle perspective, l’objet d’étude du géomètre n’est plus la figure ou ses propriétés, mais un espace. De plus, cet espace ne se présente pas comme ce « dans quoi » les figures étudiées se trouvent, c’est-à-dire comme un milieu toujours présent dont les propriétés resteraient à l’arrière-plan, mais comme un modèle abstrait d’un système axiomatique. Ces deux approches de la géométrie présentent des ressemblances (en un sens, Hilbert axiomatise bien la théorie d’Euclide), mais les différences entre elles sont essentielles. Les historiens des mathématiques parlent volontiers de la rupture hilbertienne. Pour reprendre une métaphore classique en histoire de la philosophie, on pourrait dire que les Fondements de la géométrie accomplissent une véritable révolution copernicienne : dans la géométrie classique, les propositions géométriques portent sur (tournent autour) des figures, considérées comme des objets s’insérant dans un espace donné antérieurement à la théorie ; dans la géométrie qui se situe dans la descendance de Hilbert, c’est l’inverse : le géomètre définit l’espace par un discours qui prend systématiquement la forme d’une axiomatique —le discours ici tourne autour de l’espace.
Mon propos dans ce qui suit n’est pas de remettre en cause la pertinence de l’opposition que je viens de décrire, mais de montrer que la division ne recoupe pas tout le champ des possibles. Plus précisément, je montrerai dans ce qui suit qu’il existe des cadres théoriques dans lesquels les mathématiciens ont utilisé des figures ou des diagrammes pour représenter des espaces —et, inversement, que dans ces contextes des espaces, définis axiomatiquement, ont pu être dessinés sur une feuille de papier. Ainsi, dans les géométries finies qui sont apparues au début du XXe siècle, les modèles des axiomatiques sont des figures, et les propriétés de ces figures expriment des caractéristiques de l’espace sous-jacent. Plutôt que de présenter un panorama chronologique de l’émergence de ces nouvelles géométries, je me servirai de la distinction entre figure et espace pour problématiser quelques étapes de cette histoire. Je donnerai tout d’abord quelques indications mathématiques préalables sur la notion de « configuration », qui a joué un rôle fondamental dans cette affaire. Je montrerai ensuite comment les géomètres du XIXe siècle en sont venus à distinguer deux notions de configuration : un concept « abstrait », combinatoire, d’une part, et un concept « concret », géométrique, de l’autre. Enfin, j’étudierai le début de l’article « Finite Projective Geometries » de Oswald Veblen (et de son collègue W. Bussey), véritable acte de naissance des géométries finies, pour montrer comment la substitution des espaces finis aux configurations nécessitent, pour être comprise, de remettre en question le caractère exclusif de la disjonction « figure versus espace ».
1- Préalable mathématique
Avant de définir le concept clé de configuration, donnons quelques indications sur la façon dont les mathématiciens définissent aujourd’hui la notion de structure d’incidence. Soit  B
B ABC
ABC 12)
12)
Tous les tableaux à double entrée de ce type correspondent à une structure d’incidence possible définie sur ABC12

- Figure 1.

J’ai mis ci-dessus « points » et « droites » entre guillemets pour manifester le fait que les éléments de bk)
- (i) il y a au plus une « droite » passant par deux « points » quelconques ;
- (ii) il y a
k « points » sur chaque « droite » etr « droites » sur chaque « point ». [5]
La structure
En revanche, la structure d’incidence qui comporte 4 « points » (ABCD 123456 62) 4 3 2 6
4 3 2 6 
Comme nous venons de le voir, les éléments distingués —les « points » et les « droites »— ne sont pas ici, malgré leur nom, des objets géométriques. Le diagramme précédent est un tableau à double entrée, et il peut recevoir toutes les interprétations qu’une telle structure de données est habituellement susceptible de recevoir. Mais il se trouve ici, à la différence de ce qui se passait plus haut, qu’on peut donner un sens géométrique à la configuration en question. Dans la Fig. 2, si l’on ne considère que les points BCD…6BCD…6

- Figure 2. : Réalisation géométrique de la configuration
(43  62)
62)

La figure 2 est le schéma d’un objet géométrique, et même d’un objet euclidien, si l’on entend par là que les « droites » sont représentées par des droites conformes à celles qu’Euclide considérait et non pas par des arcs de cercles comme dans la Fig. 1. Remarquons toutefois que l’objet est euclidien en un sens très particulier, puisque dans la configuration, beaucoup d’éléments considérés ordinairement comme faisant partie de la figure doivent être ignorés. Ainsi, les droites …623…D73)
Il n’est pas possible de réaliser une telle configuration en prenant, pour éléments de

- Figure 3. : Le « plan de Fano »
73

Une des questions qui traverse l’histoire de la théorie des configurations est celle de distinguer les configurations du genre de
Il se présente également un autre problème, plus délicat à décrire. Revenons, pour l’introduire, à la notion de structure d’incidence, dont nous avons vu qu’elle était complètement spécifiée par une table d’incidence. Si nous intervertissons la ligne
Il ne faudrait cependant pas croire que les configurations de genre bk)bk)

93(a)93(b)93(c)
Figure 4. : Les trois configurations93 . La seconde est la configuration de Pappus.
Il n’existe aucune possibilité de faire correspondre les lignes et les colonnes de la table d’incidence de
2- Le concept de configuration : de Reye à Moore [8]
C’est, en 1876, dans la seconde édition de son Geometrie der Lage que Theodor Reye, mathématicien allemand de l’université de Strasbourg, présente une première définition générale du terme de configuration [9] :
Une configuration
La définition est restrictive, dans la mesure où c’est seulement les configurations planaires « symétriques » (où points et droites jouent des rôles qui se font miroir) qui sont retenues. Mais surtout, Reye considère les configurations comme des objets géométriques. Une configuration d’un type donné n’est pas ici une (ou plus précisément un ensemble de) structure(s) d’incidence « abstraite », définie par une (une famille de) table(s) d’incidence : les points et les droites dont il est question dans les configurations sont pour Reye des points et des droites d’un plan —pour être précis, disons que les plans en question sont ordinaires à ceci près que deux droites quelconques s’y rencontrent toujours (on appelle de tels plans « projectifs »). Le géomètre affirme ainsi qu’il n’y a pas de configuration
Le problème des configurations est celui d’énumérer combien de configurations différentes il y a du genre
Reye, se référant aux résultats obtenus par Seligmann Kantor (un mathématicien allemand travaillant à Prague) en 1881 [11], affirme ainsi qu’il y a trois configurations

- Figure 5. : La configuration de Desargues, une des configurations
103 .

Six ans après, en 1887, un mathématicien italien, Vittorio Martinetti [12], découvre une méthode permettant de trouver le nombre de configurations symétriques

- Figure 6. : La (fausse) configuration
103 de Kantor (tiré de Gropp 2004, 82).

Comme l’on voit, il n’est pas du tout évident de déterminer en quoi la figure est incorrecte.
Schröter tire la conclusion qui s’impose en distinguant les configurations géométriquement constructibles des configurations « combinatoirement » admissibles. À la fin de son article, il reprend l’approche abstraite de Martinetti, et ajoute :
On habille ce pur problème combinatoire, consistant à construire une configuration
De la présentation qui précède, il ressort donc que la notion de configuration a d’abord été perçue comme un concept relevant de la géométrie (projective réelle) pour peu à peu s’abstraire en devenant un concept relevant de la « combinatoire ». Alors que chez Reye et Kantor, une configuration est un système d’éléments spatiaux dont on étudie les propriétés, chez Schröter, ce système est seulement « l’habit géométrique » d’une structure plus profonde, qui devrait pouvoir être décrite indépendamment de toutes considérations relatives à l’espace.
Mais Schröter ne donne aucune définition générale du concept abstrait de configuration, et on ne trouve pas chez lui la notion de structure d’incidence, telle que nous l’avons rencontrée dans la section 1. C’est le mathématicien américain E. H. Moore, dans un article intitulé Tactical Memoranda, daté de 1896, qui donne la première définition générale, sous-jacente dans le raisonnement de Schröter [14]. Moore se place dans le cadre très général d’un espace de dimension
Moore définit d’abord le concept de structure d’incidence (p. 265) et celui, connexe, de table d’incidence. Il précise que la table fournit la caractérisation complète de la relation d’incidence, « qui n’est pas autrement définie ». Il poursuit,
Ce système est appelé configuration tactique de rang h(g≠h)h=12…n
Une configuration « tactique » de rang
Pour bien comprendre comment Moore la généralise, prenons l’exemple de la configuration tridimensionnelle tétraèdre, qui peut se noter en utilisant une table de trois par trois ainsi 
 4 3 3 2 6 2 3 3 4
4 3 3 2 6 2 3 3 4 


- Figure 7. Configuration tétraèdre

Adoptant le point de vue « abstrait » de Schröter, Moore reprend ainsi la distinction entre configurations géométriquement réalisables et celles qui ne le sont pas. Le mathématicien souligne par exemple (p. 266) que
3- L’émergence des espaces finis
L’approche de Moore est « abstraite », donc en un sens déjà « moderne » si l’on entend par ce terme l’idée introduite au tout début de l’article : la configuration comme objet géométrique apparaît en effet seulement comme une interprétation de la structure combinatoire sous-jacente. J’aimerais montrer pourtant que cette « abstraction » n’est pas de même nature que celle introduite par Hilbert et sa méthode axiomatique.
En 1906, Veblen et Bussey, qui ont été élèves de Moore, publient un article fondateur, « Finite Projective Geometries », dans lequel sont élaborées, en suivant le modèle axiomatique hilbertien, les premières géométries finies (c’est-à-dire les premières géométries dans lesquelles le nombre de points et de droites et éventuellement de plans de l’espace considéré est fini). L’article de Moore y joue un rôle crucial mais ambigu. Dans la section 1 de leur article, intitulée « définition synthétique », les deux auteurs présentent une liste de cinq axiomes définissant un espace de dimension
- I L’ensemble contient un nombre fini
( de points. Il contient des sous-ensembles appelés droites, qui comportent chacun au moins trois points. 2)
2) - II Si
A etB sont des points distincts, il y a une et une seule droite qui contienneA etB . - III Si
A sont trois points n’appartenant pas tous à la même droite, et si une droiteBCI contient un pointD de la droiteAB et un pointE de la droiteBC , mais ne contient niA , niB , niC , alors la droiteI contient un pointF de la droiteCA . - IV Les points ne sont pas tous sur la même droite.
Soit donc un ensemble fini de « points » (le « plan ») et une famille de sous-ensembles (les « droites » du « plan »). L’axiome I stipule que les « droites » doivent contenir au moins trois « points », l’axiome II, que deux « points » déterminent une « droite », l’axiome IV que, quelle que soit la « droite » que l’on considère, il y a un « point » extérieur à cette « droite ». Enfin l’axiome III, légèrement plus compliqué, impose que si B

- Figure 8. L’axiome III de Veblen

Si les axiomes I, II et IV sont vérifiés dans le plan euclidien, le troisième ne l’est pas puisqu’il n’est pas compatible avec l’existence d’une droite parallèle à
Ces quatre postulats correspondent presque exactement aux axiomes qui permettent à Veblen et Young, dans leur manuel de géométrie projective de 1910 [16], de développer la totalité de la géométrie du plan projectif « ordinaire » (non fini). C’est sur cette base que Veblen et Bussey peuvent affirmer que leur théorie est une géométrie projective finie : mise à part la demande que le plan soit constitué d’un nombre fini de points, rien ne distingue leur théorie de la géométrie projective standard. Cette ressemblance justifie donc de considérer leur axiomatique comme une « géométrie ».
Bussey et Veblen montrent que la configuration
Vu de plus près toutefois, leur travail prend un autre visage. Citons l’introduction de « Finite Projective Geometries » :
Par le biais du concept généralisé de géométrie tel qu’il ressort inévitablement des recherches récentes et profondes sur les fondements de cette science, est donnée, dans le §1 de cet article, une définition d’une classe de configurations tactiques qui inclut de nombreuses configurations bien connues, ainsi que plusieurs nouvelles. Le §2 développe une méthode qui permet de construire ces configurations et qui se révèle fournir toutes les configurations satisfaisant la définition. Dans les §§4-8, on montre que les configurations ont une théorie géométrique identique, dans la plupart de ses théorèmes généraux, à la géométrie projective ordinaire (…). Dans le §9, référence est faite aux autres définitions de certaines des configurations incluses dans la classe définie dans le § 1.
Veblen et Bussey se placent non seulement dans la filiation de « recherches récentes et profondes sur les fondements » de Hilbert, mais aussi dans celle des études sur les configurations développées durant toute la fin du XIXe siècle et dont le Tactical Memoranda de Moore propose une synthèse. La liste de postulats est présentée ici, non pas comme un système axiomatique particulier, mais comme la « définition d’une classe de configurations ». Et le paragraphe 9, final, dans lequel les auteurs renvoient à Moore, vise à expliciter les liens entre le concept d’espace projectif fini et les diverses structures combinatoires déjà connues –signalons, dans un langage un peu plus technique, la connexion la plus évidente : un plan projectif d’ordre [17]
L’adoption du nouveau schéma hilbertien, loin donc de constituer une rupture radicale par rapport aux anciennes recherches, permet donc de reformuler les questions liées aux configurations dans un nouveau cadre, explicitement considéré comme « géométrique ». Mais la question se pose alors de comprendre en quel sens exactement on entend désormais ce qualificatif de « géométrique ».
Caractériser les recherches de Veblen et Bussey de « géométriques » ne signifie pas, bien entendu, qu’on les assimile à celles, pré-combinatoires, de Reye et Kantor. Les espaces projectifs ne sont pas des figures, comme les configurations l’étaient chez les deux précurseurs. Veblen et Bussey adoptent le point de vue « abstrait » de Moore : les configurations ne sont pour eux que des familles de structures d’incidence. Leur idée est cependant qu’il est possible d’appliquer à l’étude de ces systèmes d’éléments abstraits, des concepts et des méthodes issus de la géométrie. Plus précisément, ils conçoivent ces systèmes comme des modèles de la théorie projective finie.
Cette réintroduction de la géométrie dans la combinatoire se manifeste de façon particulièrement spectaculaire dans le traitement par Veblen et Bussey de la configuration
Il y a ici une inversion extrêmement frappante :
Bien entendu, c’est « le concept généralisé de géométrie, tel qu’il ressort inévitablement des recherches récentes et profondes sur les fondements de cette science », c’est-à-dire les Fondements de Hilbert, qui explique ce renversement (la configuration
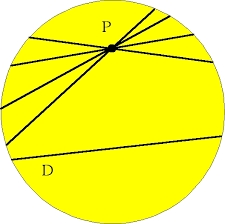
D’une certaine façon, même lorsqu’une configuration est conçue comme un objet géométriquement réalisable, elle possède déjà une certaine indépendance, une certaine autonomie, par rapport à son plan d’inscription. Nous avions noté que la Fig. 2, celle de la configuration de quatre points et de six droites, pouvait difficilement être considérée comme une figure euclidienne, dans la mesure où, chez elle, certains éléments qui d’ordinaire seraient considérés comme faisant partie du schéma devaient en être exclus. Toujours dans le même ordre d’idées, j’ai choisi, dans la Fig. 1, de représenter la droite
Les configurations n’ont aucun hors-champ que l’on pourrait utiliser à discrétion pour introduire ce qui nous est nécessaire dans les démonstrations. Les relations d’incidence entre les points et les droites y sont fixées dès le début, et toute modification de ces relations détruit le système que l’on considère. Le regard qui parcourt une configuration géométrique n’est ainsi pas le même que celui qui étudie une figure euclidienne. L’attention est focalisée sur le nombre d’intersections – elle n’est pas tendue par la possibilité d’enrichir ou de diviser la figure.
Veblen et Bussey, en construisant leurs nouvelles géométries, ne font donc qu’accomplir ce mouvement d’autonomisation contenu en germe dans la notion de configuration. La tendance à détacher la figure de son inscription dans un espace atteint son apogée dans le concept de plan projectif fini : le plan de Fano n’est pas le dessin d’une figure sur une feuille – il est censé se substituer à la feuille sur laquelle on dessine.
Conclusion
Que Veblen et Bussey s’inscrivent dans le projet de refondre axiomatiquement la géométrie n’empêche pas leur travail de prolonger et radicaliser les premières recherches sur les configurations. L’étude des géométries finies est ainsi un bon belvédère pour observer et tenter de mesurer in concreto l’impact des Fondements de la géometrie sur la pratique des géomètres.
Veblen, comme Moore d’ailleurs [18], ont lu Hilbert très précisément, et, avec d’autres mathématiciens américains (les travaux de ce groupe sont connus étant ceux de l’« école postulationniste » [19] ), ils entreprennent d’appliquer la nouvelle méthode à des champs très différents (théorie algébriques, géométriques, etc).
Dans l’article sur la géométrie finie de 1906, l’utilisation du modèle hilbertien rencontre toutefois un mouvement d’abstraction déjà fort abouti – celui qui a mené les mathématiciens des configurations considérées comme des objets géométriques aux configurations combinatoires abstraites. Dans ce contexte, l’axiomatisation n’est pas seulement une étape supplémentaire vers l’abstraction – ironiquement, elle se présente même comme un mouvement inverse, comme un retour vers la géométrie.
La nouvelle approche permet en effet d’appliquer les concepts et les techniques géométriques à des situations et des problèmes purement combinatoires. Essayer de préciser l’impact des Fondements sur les mathématiciens américains travaillant sur les configurations permet donc de mesurer combien la révolution copernicienne que représente l’approche hilbertienne intègre des éléments qui appartiennent à un socle plus ancien.
Plus généralement, l’opposition souvent reprise entre géométrie de la figure et géométrie de l’espace a l’inconvénient de présupposer que le mode d’insertion de la figure dans un espace n’est pas vraiment un problème digne de l’attention de l’historien. Dans la perspective de la dichotomie entre espace et figure, soit on se concentre sur la figure, et dans ce cas, la question de la nature de l’espace dans lequel « vit » la figure ne peut par principe pas être explicitée ; soit on axiomatise l’espace sous-jacent, mais alors l’étude des triangles et des cercles, des courbes et des droites, devient secondaire et disparaît de l’horizon.
Or, il semble que le rapport entre la figure à son « environnement » (à son « support », et même à la matérialité de ce support) ait parfois été une question pour les mathématiciens (qu’ils précèdent Hilbert ou qu’ils le suivent). Elle devrait donc l’être aussi pour les historiens des mathématiques. La feuille sur laquelle le géomètre trace ses figures a des bords – n’est-il pas possible prendre en compte l’existence de ces limites dans la pratique géométrique elle-même [20] ?
Certaines sortes de « figures » (mais faut-il encore les appeler ainsi ?), les configurations, dans lesquelles les rapports à l’espace « environnant » sont comme suspendus, ont peu à peu été prises pour sujet d’étude par les géomètres au XIXème siècle – comment caractériser ces nouveaux objets ?
Enfin, les mathématiciens qui travaillent de nos jours en géométrie discrète et plus généralement en combinatoire utilisent abondamment des figures et même des stéréogrammes [21] pour représenter les espaces qu’ils considèrent – quel statut accorder à ces figures-espaces ? Ce qui précède doit être lu comme une invitation à poser ce genre de questions [22]
Notes
[1] Hilbert D., Les fondements de la géométrie (1899), trad. fr. P. Rossier, Gabay, 2000.
[2] Le premier axiome stipule que deux points déterminent une droite, le second que l’on peut prolonger continûment en ligne droite une droite limitée donnée, le troisième que l’on peut construire un cercle lorsque l’on dispose de son rayon et son centre, le quatrième que tous les angles droits sont égaux entre eux. Le cinquième axiome a toujours eu un statut particulier : il s’agit de l’axiome des parallèles, qui revient à demander que, par un point extérieur à une droite donnée, il ne passe qu’une et qu’une seule parallèle à cette droite.
[3] Il en va notamment ainsi des propositions qui mettent en jeu des considérations tenant à la continuité, au déplacement ou encore à l’« ordre » (c’est-à-dire à ce qui est relatif, par exemple, à la distinction entre intérieur et extérieur d’une courbe close, ou à l’opposition entre demi-plan droit et gauche, etc.).
[4] La formulation des axiomes varie selon les éditions. Mais la division en cinq groupes reste constante : les 7 axiomes « d’appartenance » posent des conditions sur les relations d’incidence entre points, droites et plans ; les 5 axiomes d’ordre donnent un sens à l’expression « être entre deux points » et à la notion de demi-plan ; l’axiome des parallèles reprend le contenu du postulat d’Euclide ; les 5 postulats de congruence définissent l’égalité entre les segments et entre les aires ; enfin Hilbert ajoute deux axiomes de continuité.
[5] Par souci de symétrie, on parle de « droite » sur un point comme on parlait de « point » sur une droite.
[6] Les nombres qui figurent dans la diagonale (qui va de gauche à droite en descendant) correspondent aux nombres de « points » et de « droites » de la configuration (4 « points » et 6 « droites ») ; les autres nombres indiquent le nombre de « points » situés sur chaque « droite » (2) et le nombre de « droites » rencontrant chaque « point » (3).
[7] E. Steinitz, Über die Construction der Configurationen
[8] Dans toute cette section, je reprends les conclusions de l’article très éclairant de H. Gropp, « Configurations between geometry and combinatorics », Discrete Applied Mathematics, (2004), 138, pp. 79-88, auquel je renvoie le lecteur pour plus de précisions.
[9] Th. Reye, Geometrie der Lage, (1867), C. Jümpler, Hannover, 2nd edition, 1876. La notion de configuration est historiquement liée au développement de la géométrie projective au XIXe siècle. Cela n’est pas surprenant, dans la mesure où la géométrie projective est progressivement devenue une théorie portant sur les relations d’intersection et d’appartenance (c’est-à-dire les relations d’incidence) entre les points, les droites et les plans dans l’espace. Mais ce n’est que relativement tardivement que, dans le contexte de ses recherches sur la théorie projective, Theodor Reye introduit cette première définition générale de la configuration.
[10] Th. Reye, “Das Problem der Configurationen”, (1882), Acta Mathematica, 1, pp. 93–96.
[11] S. Kantor, “Die Configurationen
[12] V. Martinetti, “Sulle le configurazione piani  33
33
[13] H. Schröter, “Ueber die Bildungsweise und geometrische Construction der Configurationen”, (1889), Göttinger Nachrichten, pp.193–236. Pour de plus amples détails, voir Gropp 2004, 83-85.
[14] « Tactical Memoranda », American Journal of Mathematics, (1896), 18, pp.264-303. Moore explique que « sous le titre général de Tactical Memoranda », il « publiera une série d’articles concernant des sujets plus ou moins liés entre eux de Tactique ». Pour une définition de « tactique », Moore renvoie à Cayley (« On the Notion of Boundaries of Algebra », Quarterly Journal of Mathematics, 6, 1864, Collected Math. Papers, V). Un problème tactique est pour Cayley un problème de combinatoire.
[15] L’exemple est tiré de O. Veblen & J. W. Young, Projective Geometry, I, 1910, New York : Ginn and Company, pp. 38-40.
[16] Voir O., Veblen & J. W. Young, Projective Geometry, op. cit.… , pp.15-19.
[17] Lorsque sa dimension est supérieure ou égale à 3, un espace projectif peut toujours être défini à partir d’un espace vectoriel (le cas
[18] E. H. Moore, “On the foundations of mathematics”, Bulletin of the American Mathematical Society, (1903), 9, pp. 402-424.
[19] M. J. Scanlan, “Who were the American postulate theorists”, Journal of Symbolic Logic, (1991), 56, pp. 981-1002.
[20] J’ai discuté cette question dans « Pasch entre Klein et Peano : empirisme et idéalité en géométrie », Dialogue, (2005), 14, pp. 653-692.
[21] B. Polster, A Geometrical Picture Book, Springer, 1998
[22] Je remercie chaleureusement Karine Chemla pour l’aide qu’elle m’a apportée dans la construction de cet article.
Source : http://images.math.cnrs.fr/Entre-figures-et-espaces-le-ca...
20:00 Publié dans Entre figures et espaces : le cas des diagrammes | Lien permanent | Commentaires (0) | Tags : entre figures et espaces : le cas des diagrammes en géométrie fi | | del.icio.us | | Digg | Facebook
INITIATION AUX MATHÉMATIQUES FINANCIÈRES
INITIATION AUX MATHÉMATIQUES FINANCIÈRES
J.Azéma
Date: Février 2004
Ces notes , destinées aux étudiants de la maitrise MASS de l'université Paris V , ne prétendent à aucune originalité. Elles ont pour but d'aider les étudiants de ce cursus, possèdant pour certains d'entre eux un bagage mathématique réduit ,à comprendre le début du remarquable petit livre de
Lamberton et Lapeyre intitulé "Introduction au calcul stochastique appliqué à la finance" Ed.Ellipses (97) ;la lecture des 40 premières pages de cet ouvrage est , bien entendu , fortement recommandée.
Le problème principal que nous nous poserons est celui de l'évaluation du prix d'une option (pricing) ; voici en gros de quoi il s'agit. Et tout d'abord de quoi il ne s'agit pas : on ne cherche en aucune façon à prédire l'évolution du cours d'une action ; ce travail est celui des analystes financiers qui auscultent le bilan de la firme , ses avantages ou ses handicaps vis à vis de la concurrence , regardent si elle est positionnée sur un marché porteur , etc...Cela fait, ils prodiguent à leurs clients ou publient dans la presse financière des conseils d'achat ou de vente.
Mais cette même action peut servir de support à des options d'achat (call) ou de vente (put) dont le fonctionnement peut être décrit de la manière suivante.
L'acheteur d'une option achète un droit à son émetteur ( en général un grand établissement financier) qu'il pourra ou non exercer à une date convenue à l'avance appelée date d'exercice. S'il s'agit d'un call, ( resp.d'un put), ce droit consiste en la possibilité pour le détenteur de l'option d'acheter, (resp.de vendre), l'action support à son émetteur à un prix, lui aussi déterminé à l'avance, appelé prix d'exercice.
Il est à noter
- que l'acheteur de l'option paye immédiatement son dû , à savoir le prix de l'option, à son vendeur ; celui ci dipose donc de liquidités qu'il peut faire fructifier a sa guise jusqu'à la date d'exercice.
- que si le détenteur de l'option peut choisir d'exercer ou non son droit, son vendeur est tenu de respecter le contrat en cas d'exercice de l'option.
Au
- soit acheter 100 actions Michelin
- soit acheter a la Société Générale 2000 call sur Michelin
Mais ce petit miracle a une contrepartie : si l'action Michelin, contrairement à votre attente, perd 5% au cours de l'année, elle cotera 190F à la date d'exercice ; le droit que vous avez acquis (la possibilité de l'acheter a 220F) n'a plus aucune utilité et donc aucune valeur ; il ne vous reste plus qu'à jeter votre option à la corbeille et à constater, en gardant le sourire, que vous avez perdu la totalité de votre investissement initial de 20.000F
Le mécanisme de l'option de vente est exactement inverse : c'est un outil de spéculation à la baisse avec un risque de ruine en cas de hausse ; si vous achetez un put doté des memes caractéristiques, et si le cours de l'action support a perdu 20%, elle cote 160F à la date d'exercice ; vous achetez alors sur le marché boursier 2000 actions à 160F que vous revendez 220F à la Société Générale ; je vous laisse calculer votre bénéfice...
Ces options ont une autre fonction ; supposons qu'un fonds de pension américain détienne 30% du capital de Michelin et s'attende à une forte baisse du cours de l'action ; il peut, bien entendu , vendre sa participation avant la catastrophe annoncée, mais, pour des raisons fiscales, ou pour ne pas perdre son droit de regard sur la gestion de l'entreprise, il préfèrera souvent recourir à une stratégie de couverture des risques (hedging) fondée sur l'achat d'options de vente. En cas d'effondrement du marché, les gains procurés par la possession de ces put, amplifiés par l'effet de levier qui vient d'être décrit, permettront de compenser la perte provoquée par la chute des cours. Plus que le goût de la spéculation prêté aux anglo-saxons, c'est vraisemblablement ce souci de sécurité qui explique le développement spectaculaire des marchés dérivés constaté au cours des 20 dernières années aux Etats Unis.
Il reste à expliquer le rôle que jouent les mathématiques dans cet univers ; une étude statistique des cours de bourse conduit tout d'abord a une estimation de la loi de probabilité qui gouverne leur évolution ; répétons qu'il ne s'agit pas ici de formuler des prédictions ; pour prendre un exemple analogue , il s'agit , après observation d'un grand nombre de jets d'une pièce de monnaie , d'établir que la probabilité de tomber sur pile est (à peu près) 1/2 ; dans ces notes , nous supposerons ce problème résolu à l'aide des techniques classiques de la statistique des processus , et nous supposerons donc cette loi connue. La tâche qui incombe alors à l'équipe de probabilistes salariés par la Société Générale est de déterminer à quel prix vendre ses options (les 10F de notre exemple); vendues trop chères, personne n'en voudra, vendues trop bon marché , elles peuvent conduire à la faillite des établissements réputés indestructibles , (toujours ce dévastateur effet de levier) . Ce dernier point n'est pas une exagération : les faillites retentissantes (Baring , LTCB,etc..) qui ont récemment semé la panique sur les marchés financiers sont presque toutes dues a des spéculations malheureuses sur les marchés dérivés .
Nous nous bornerons, pour l'essentiel , à l'étude du modèle discret de Cox, Ross et Rubinstein dans lequel on suppose que le marché financier est réduit a un actif risqué (par exemple une action) et à un actif sans risque (par exemple un carnet d'épargne à taux fixe) . On fait en outre les hypothèses simplificatrices suivantes:
- Le temps est discret (on ne s'intéresse par exemple au cours des actifs qu'à la clôture de la bourse chaque jour a 17H)
- l'actif risqué n'a que 2 comportements possibles : son cours est multiplié chaque jour par une quantité aléatoire qui ne peut prendre que 2 valeurs fixées (par exemple, à chaque clôture ce cours est soit multiplié par 2 soit divisé par 3) .
En dépit de son caractère simpliste, l'étude de ce modèle est instructive pour plusieurs raisons ; tout d'abord les méthodes employées sont en tout point analogues à celles qui conduisent aux résultats de Black and Scholes et ceci dans un cadre élémentaire . On peut déjà y discerner le rôle fondamental joué par la théorie des martingales ainsi que les raisons d'un certain nombre de résultats assez surprenants du modèle de B. and S. , le fait que le prix d'une option dépende uniquement de la volatilité du marché et non pas de sa tendance (haussière ou baissière) par exemple.
Mais il va nous falloir faire un peu de mathématiques ; au travail!
- Rappels
- L'espace des épreuves
- Les variables aléatoires et leurs lois
- Indépendance
- Indépendance d'une famille d'événements:
- Indépendance de deux classes :
- Indépendance d'une famille de variables aléatoires
- Indépendance et produit de lois :
- Existence et unicité en loi d'une suite de variables aléatoires indépendantes équidistribuées.
- Proposition
- Exemple: une autre approche de la loi binomiale
- Espérance d'un produit de variables aléatoires indépendantes:
- Variance d'une somme de v.a.r. indépendantes
- Exercice:
- Conditionnement
- Conditionnement par un événement
- Conditionnement par une variable aléatoire
- Algèbres et partitions
- Martingales
- Mathématiques des marchés financiers
- Le modèle de Cox, Ross et Rubinstein
- Les options américaines
- La formule de Black and Scholes
19:40 Publié dans INITIATION AUX MATHÉMATIQUES FINANCIÈRES | Lien permanent | Commentaires (0) | Tags : initiation aux mathÉmatiques financiÈres | | del.icio.us | | Digg | Facebook
Mathématiques Financières : l’essentiel
| Mathématiques Financières : l’essentiel |
Rappels d’algèbreTaux proportionnel - Taux équivalent Capitalisation - Actualisation
Emprunts indivis - Annuités (fin de période)
|


19:35 Publié dans Mathématiques Financières : l’essentiel | Lien permanent | Commentaires (0) | Tags : mathématiques financières : l’essentiel | | del.icio.us | | Digg | Facebook
06/01/2010
Construction de Z à partir de N
En supposant connues les propriétés élémentaires de l'ensemble ![]() et de l'addition des entiers naturels, nous allons donner une construction rigoureuse de
et de l'addition des entiers naturels, nous allons donner une construction rigoureuse de ![]() et de l'addition des entiers relatifs. Dans cette construction,
et de l'addition des entiers relatifs. Dans cette construction, ![]() apparaîtra sous forme d'un quotient de
apparaîtra sous forme d'un quotient de ![]() par une relation d'équivalence. Ce paragraphe est aussi l'occasion de rappeler les notions de relation d'équivalence et d'ensemble quotient, notions centrales pour le reste du cours.
par une relation d'équivalence. Ce paragraphe est aussi l'occasion de rappeler les notions de relation d'équivalence et d'ensemble quotient, notions centrales pour le reste du cours.
Définition Soit ![]() un ensemble. Une relation sur
un ensemble. Une relation sur ![]() est un ensemble
est un ensemble ![]() de couples d'éléments de
de couples d'éléments de ![]() . On écrit
. On écrit ![]() au lieu de
au lieu de ![]() . Une relation
. Une relation![]() est une relation d'équivalence si elle est
est une relation d'équivalence si elle est
- a)
- réflexive (i.e. pour tout
 , on a
, on a  )
) - b)
- symétrique (i.e. on a équivalence entre
 et
et  quels que soient
quels que soient  )
) - c)
- transitive (i.e. les conditions et
 impliquent que
impliquent que  quels que soient
quels que soient  )
)
[2)] Soit ![]() et définissons
et définissons ![]() par
par
Par exemple, on a
En rajoutant la première à la seconde on obtient
ou encore
Or on sait que la loi d'addition sur
Définition Soit ![]() un ensemble et
un ensemble et ![]() une relation d'équivalence
une relation d'équivalence![]() sur
sur ![]() . Pour
. Pour ![]() , on pose
, on pose
et on appelle classe d'équivalence de ![]() par rapport à
par rapport à ![]() cette partie de
cette partie de ![]() . Par définition, l'ensemble
. Par définition, l'ensemble ![]() est formé des classes
est formé des classes ![]() d'éléments
d'éléments ![]() . On appelle
. On appelle![]() le quotient de
le quotient de ![]() par la relation d'équivalence
par la relation d'équivalence ![]() . On définit l'application quotient (=la projection canonique)
. On définit l'application quotient (=la projection canonique) ![]() par
par ![]()
![]() . Une partie de
. Une partie de ![]() est un système de représentants pour
est un système de représentants pour ![]() si elle contient un élément de chaque classe d'équivalence et un seul.
si elle contient un élément de chaque classe d'équivalence et un seul.
Il existe beaucoup de systèmes de représentants. Par exemple, l'ensemble
[2)] Dans le cas de l'exemple ![]() et de la relation
et de la relation ![]() introduite ci-dessus on vérifie que
introduite ci-dessus on vérifie que ![]() si et seulement si l'une des deux conditions suivantes est remplie
si et seulement si l'une des deux conditions suivantes est remplie
- il existe
 tel que
tel que  et
et 
- il existe tel que
 et
et  .
.
![includegraphics[width=10.0cm height=10.0cm]{classesNN.eps}](http://www.les-mathematiques.net/b/a/d/img60.png)
Il y a beaucoup de systèmes de représentants. Par exemple
en est un. On définit l'ensemble
Lemme [Propriété universelle de ![]() ] Soit
] Soit ![]() un ensemble,
un ensemble, ![]() une relation d'équivalence
une relation d'équivalence![]() sur
sur ![]() et
et ![]() une application constante sur les classes d'équivalence
une application constante sur les classes d'équivalence![]() par rapport à
par rapport à ![]() (c'est-á-dire qu'on a
(c'est-á-dire qu'on a ![]() à chaque fois que
à chaque fois que ![]() ). Alors il existe une application
). Alors il existe une application ![]() et une seule telle que
et une seule telle que![]() . Réciproquement, toute application de la forme
. Réciproquement, toute application de la forme ![]() est constante sur les classes d'équivalence.
est constante sur les classes d'équivalence.
![begin{picture}(14,8)(0,0) % multiput(0,0)(1,0){15}{ line(0,1){8}} % multi... ...3.5){makebox(0,0)[tl]{$ ;g $}} put(6,6.2){makebox(2,2){$ f $}} end{picture}](http://www.les-mathematiques.net/b/a/d/img69.png)
Démonstration. On pose ![]() . Il s'agit de vérifier que
. Il s'agit de vérifier que ![]() est indépendant du représantant
est indépendant du représantant ![]() de la classe
de la classe ![]() . Or si
. Or si ![]() en est un autre, c'est-à-dire que
en est un autre, c'est-à-dire que![]() , alors par définition, on a
, alors par définition, on a ![]() et donc
et donc ![]() .
. ![]()
Lemme [Addition sur ![]() ] Il existe une application
] Il existe une application
et une seule telle que
Démonstration. Il s'agit de montrer que ![]() si
si ![]() et
et ![]() . Nous laissons au lecteur le soin de cette vérification.
. Nous laissons au lecteur le soin de cette vérification.![]()
Définition Un groupe est un couple ![]() formé d'un ensemble
formé d'un ensemble ![]() et d'une application
et d'une application
appelée la loi du groupe telle que
- a)
- la loi
 est associative (i.e. on a
est associative (i.e. on a  quels que soient
quels que soient  )
) - b)
- la loi admet un élément neutre (i.e. il existe
 tel que
tel que  quel que soit
quel que soit  )
) - c)
- tout élément
 de
de  admet un inverse
admet un inverse  pour la loi (i.e. on a
pour la loi (i.e. on a  )
)
Un groupe ![]() est commutatif si on a
est commutatif si on a ![]() quels que soient
quels que soient ![]() .
.
[2)] Si les conditions a), b) et c) sont vérifiées, l'élément inverse ![]() de la conditon c) est unique. En effet, supposons que
de la conditon c) est unique. En effet, supposons que ![]() et
et ![]() sont deux éléments inverses à
sont deux éléments inverses à ![]() . Alors on a
. Alors on a
On note
[2)] Le couple ![]() est un groupe. En effet, on vérifie facilement l'associativité. L'élément neutre est la classe de
est un groupe. En effet, on vérifie facilement l'associativité. L'élément neutre est la classe de ![]() . L'inverse de la classe de
. L'inverse de la classe de ![]() est la classe de
est la classe de ![]() ! En effet, nous avons
! En effet, nous avons
Lemme [Propriété universelle de ![]() ] Soit
] Soit ![]() l'application
l'application
On a ![]() et si
et si ![]() est une autre application de
est une autre application de ![]() vers un groupe
vers un groupe![]()
![]() telle que
telle que ![]() , alors il existe une application
, alors il existe une application ![]() et une seule telle que a)
et une seule telle que a) ![]() et b)
et b) ![]() quels que soient
quels que soient ![]() .
.
Démonstration. Il est immédiat que ![]() est additive. Supposons donnée une application
est additive. Supposons donnée une application ![]() comme dans l'énoncé. Définissons
comme dans l'énoncé. Définissons ![]() par
par![]() . Montrons que
. Montrons que ![]() induit une application
induit une application ![]() , Supposons que
, Supposons que ![]() et donc que
et donc que ![]() . Alors pour montrer que
. Alors pour montrer que
il suffit de montrer que
En utilisant que ![]() nous sommes ramenés à montrer que
nous sommes ramenés à montrer que
ce qui est clair car ![]() et
et ![]() . Montrons l'unicité de
. Montrons l'unicité de ![]() . En effet, si
. En effet, si ![]() et
et ![]() vérifient les hypothèses, nous avons
vérifient les hypothèses, nous avons
En outre, si ![]() , alors
, alors ![]() et
et ![]() sont tous les deux inverses de
sont tous les deux inverses de ![]() où
où ![]() . Donc
. Donc ![]() . Comme les
. Comme les ![]() et les
et les ![]() ,
, ![]() , forment un système de représentants des classes d'équivalence par rapport à
, forment un système de représentants des classes d'équivalence par rapport à ![]() , il s'ensuit que
, il s'ensuit que ![]() .
. ![]()
15:38 Publié dans Construction de Z à partir de N | Lien permanent | Commentaires (0) | Tags : construction de z à partir de n | | del.icio.us | | Digg | Facebook
Propriétés de l'intégrale de Riemann
Propriétés de l'intégrale de Riemann

En particulier, on a
![$displaystyle (b-a)inf f([a,b]) le int_a^b f(x),rd x le (b-a) sup f([a,b]) ~. eqno{(iIs)} $](http://www.les-mathematiques.net/a/d/a/img134.png)
Démonstration L'inégalité ![]() est conséquence immédiate de la définition de
est conséquence immédiate de la définition de ![]() resp.
resp. ![]()
![]() . Pour montrer
. Pour montrer ![]() , il suffit de prendre
, il suffit de prendre ![]() .
.
Théorème [de Chasles] Soit ![]() . Alors,
. Alors,![]()
et on a la relation de Chasles :

Démonstration Pour tout ![]() , on a évidemment
, on a évidemment ![]() et
et ![]() . Ceci entraîne
. Ceci entraîne![]() . Le même s'applique à
. Le même s'applique à ![]() . Ainsi l'intégrabilité sur
. Ainsi l'intégrabilité sur ![]() et
et ![]() implique celle sur
implique celle sur ![]() , et la relation de Chasles. Réciproquement, tout
, et la relation de Chasles. Réciproquement, tout ![]() qui contient
qui contient ![]() se décompose en
se décompose en ![]() avec
avec ![]() , et on a les mêmes relations pour les sommes de Darboux. Pour passer à
, et on a les mêmes relations pour les sommes de Darboux. Pour passer à ![]() et
et ![]() , on peut toujours supposer
, on peut toujours supposer ![]() , quitte à l'ajouter, sans perte de généralité. On en déduit le théorème. (Exercice: détailler cette démonstration.)
, quitte à l'ajouter, sans perte de généralité. On en déduit le théorème. (Exercice: détailler cette démonstration.)

et pour
Remarque Avec ces conventions, la relation de Chasles est valable quel que soit l'ordre de ![]() (par exemple aussi pour
(par exemple aussi pour ![]() ). C'est en effet la principale motivation pour ces définitions, ce qui laisse deviner l'utilité et importance de cette relation dans les applications.
). C'est en effet la principale motivation pour ces définitions, ce qui laisse deviner l'utilité et importance de cette relation dans les applications.
Il convient d'être très vigilant concernant cette généralisation lorsqu'on utilise des inégalités (telles que celles de la Prop. ![[*]](http://www.les-mathematiques.net/images/crossref.png)
![]() ), qui ne sont généralement valables que pour
), qui ne sont généralement valables que pour![]() .
.
Proposition ![]()
![]() est un sous-espace vectoriel
est un sous-espace vectoriel![]() du
du ![]() -espace vectoriel
-espace vectoriel![]()
![]() des fonctions de
des fonctions de ![]() dans
dans ![]() , et
, et ![]() ,
, ![]() est une forme linéaire
est une forme linéaire![]() sur
sur ![]() . Autrement dit,
. Autrement dit, ![]() et surtout
et surtout
et

Démonstration Les sommes de Darboux ne sont pas linéaires (car ![]() et
et ![]() ne sont pas additives). Passons donc par les sommes de Riemann, dont la linéarité,
ne sont pas additives). Passons donc par les sommes de Riemann, dont la linéarité,![]() , est évidente, ce qui donne, par passage à la limite
, est évidente, ce qui donne, par passage à la limite ![]() , le résultat souhaité. (Exercice: détailler ceci...)
, le résultat souhaité. (Exercice: détailler ceci...)



Démonstration (1): ![]() et
et ![]() .
.
(2): ![]() .
.
(3): on a ![]() , avec le (2) donc
, avec le (2) donc ![]() et
et ![]() .
.
Remarque La réciproque du (1) est évidemment fausse, ![]() n'implique pas
n'implique pas ![]() . (Contre-exemple:
. (Contre-exemple: ![]() sur
sur ![]() .)
.)
Remarque Dans le cas ![]() ,
, ![]() , on a que
, on a que ![]() est l'aire de l'épigraphe
est l'aire de l'épigraphe
Théorème [de la moyenne] Soit ![]() (fonction continue de
(fonction continue de ![]() ). Alors
). Alors
![% latex2html id marker 4186 $displaystyle exists cin[a,b]:underbrace{ frac1{b-a}int_a^b f(x)dx }_{text{moyenne de $f$ sur $[a,b]$}} = f(c) $](http://www.les-mathematiques.net/a/d/a/img186.png)
Démonstration ![]() étant continue, on a
étant continue, on a
D'après l'éq.

D'après le thm. des valeurs intermédiaires

15:36 Publié dans Propriétés de l'intégrale de Riemann | Lien permanent | Commentaires (0) | Tags : propriétés de l'intégrale de riemann, riemann | | del.icio.us | | Digg | Facebook
Intégrale de Riemann
Intégrale de Riemann
Le programme ne précise pas si la définition de l'intégrale de Riemann doit figurer dans le cours. Certains collègues commencent ce cours directement avec la définition de la primitive d'une fonction, et ![]() Ainsi, le théorème fondamental de l'analyse, qui établit le lien entre l'intégration et la dérivation, devient trivial.
Ainsi, le théorème fondamental de l'analyse, qui établit le lien entre l'intégration et la dérivation, devient trivial.
A mon avis, ce cours est quand même l'occasion ou jamais de définir l'intégrale de Riemann. Même si on passe sur les détails, on peut donner les trois définitions de ce premier chapitre et évoquer l'interprétation géométrique qui est très liée à la définition des sommes de Darboux.
Subdivisions et sommes de Darboux
Définition Une subdivision d'ordre ![]() d'un intervalle
d'un intervalle ![]() est une partie finie
est une partie finie ![]() telle que
telle que
On notera
Exemple [subdivision équidistante] Lorsque ![]() avec
avec ![]() , on parle de la subdivision équidistante d'ordre
, on parle de la subdivision équidistante d'ordre ![]() de
de ![]() ; on la note parfois
; on la note parfois ![]() . Le nombre
. Le nombre ![]() est le pas (uniforme) de cette subdivision.
est le pas (uniforme) de cette subdivision.
Définition La somme de Darboux inférieure resp. supérieure de ![]() relativement à une subdivision
relativement à une subdivision![]()
![]() sont définies par
sont définies par
 resp. resp.  |
où
Les sommes de Darboux sont des réels bien définis ssi la fonction ![]() est bornée,
est bornée, ![]() .
.
Sauf mention du contraire, dans tout ce qui suit, les fonctions considérées seront toujours bornées sur l'intervalle en question, sans que celà soit nécessairement dit explicitement.
Remarque Etudier l'interprétation géométrique des sommes de Darboux comme aire des rectangles de base ![]() , encadrant l'épigraphe de
, encadrant l'épigraphe de ![]() de en-dessous resp. au-dessus.
de en-dessous resp. au-dessus.
![includegraphics[width=10.0cm,height=8.0cm]{A1.eps}](http://www.les-mathematiques.net/a/d/a/img40.png)
Exercice Montrer qu'en ajoutant un point ![]() (entre
(entre ![]() et
et ![]() ) à
) à ![]() , la somme de Darboux inférieure
, la somme de Darboux inférieure![]() (resp. supérieure) croît (resp. décroît). En déduire qu'on a
(resp. supérieure) croît (resp. décroît). En déduire qu'on a
Utiliser le résultat précédent et la subdivision
Solution
Remarque Lorsque ![]() pour
pour ![]() , on dit que
, on dit que ![]() est plus fine que
est plus fine que ![]() . (C'est une relation d'ordre partiel
. (C'est une relation d'ordre partiel![]() sur
sur ![]() .)
.)
Fonctions Riemann-intégrables, intégrale de Riemann
Définition La fonction ![]() est Riemann-intégrable sur
est Riemann-intégrable sur ![]() ssi les deux nombres
ssi les deux nombres![]()
coïncident ; ce nombre est alors appellé l'intégrale de Riemann de
L'ensemble des fonctions Riemann-intégrables
Remarque L'existence de ![]() et
et ![]() est évidente: il suffit de constater que les ensembles
est évidente: il suffit de constater que les ensembles ![]() et
et ![]() sont non-vides (prendre
sont non-vides (prendre ![]() ) et majorés resp. minorés d'après l'exercice précédent. On peut aussi montrer que
) et majorés resp. minorés d'après l'exercice précédent. On peut aussi montrer que ![]() et
et ![]() sont atteints lorsque le pas de la subdivision,
sont atteints lorsque le pas de la subdivision, ![]() tend vers zéro. La taille de ce pas induit la structure d'une base de filtre sur
tend vers zéro. La taille de ce pas induit la structure d'une base de filtre sur ![]() , permettant de considérer la limite de
, permettant de considérer la limite de ![]() et
et ![]() en
en ![]() .
.
Remarque Revenir sur l'interprétation géométrique de ![]() et
et ![]() , en considérant la limite de subdivisions de plus en plus fines.
, en considérant la limite de subdivisions de plus en plus fines.
Remarque La ``variable d'intégration'' ![]() dans
dans ![]() est une ``variable muette'', elle peut être remplacée par n'importe quelle autre variable (qui n'intervient pas déjà ailleurs dans la même formule).
est une ``variable muette'', elle peut être remplacée par n'importe quelle autre variable (qui n'intervient pas déjà ailleurs dans la même formule).
Donnons encore une propsition d'ordre plutôt technique, avant d'énoncer une condition d'intégrabilité suffisante dans tous les cas que nous allons rencontrer.
Proposition (Critère d'intégrabilité de Riemann.) Une fonction ![]() est Riemann-intégrable sur
est Riemann-intégrable sur ![]() ssi pour tout
ssi pour tout ![]() il existe une subdivision
il existe une subdivision ![]() telle que
telle que![]() .
.
Démonstration Par déf. de ![]() et
et ![]() ,
, ![]() et
et ![]() . Avec
. Avec ![]() , il vient que
, il vient que ![]() . Donc si
. Donc si ![]() , on a la subdivision souhaitée. Réciproquement, si une telle subdivision existe pour tout
, on a la subdivision souhaitée. Réciproquement, si une telle subdivision existe pour tout ![]() , alors
, alors ![]() et
et ![]() coïncident évidemment.
coïncident évidemment.
Théorème Toute fonction monotone ou continue sur un intervalle ![]() est Riemann-intégrable.
est Riemann-intégrable.
Démonstration Si ![]() est monotone, le
est monotone, le ![]() et
et ![]() est atteint au bord de chaque sous-intervalle
est atteint au bord de chaque sous-intervalle ![]() . On a donc
. On a donc![]() . Il suffit donc de choisir le pas de la subdivision assez petit,
. Il suffit donc de choisir le pas de la subdivision assez petit, ![]() , pour que ceci soit inférieur à un
, pour que ceci soit inférieur à un ![]() donné, d'où l'intégrabilité d'après le critère de Riemann.
donné, d'où l'intégrabilité d'après le critère de Riemann.
Pour une fonction continue, la démonstration est admise dans le cadre de ce cours. A titre indicatif: ![]() est à remplacer par
est à remplacer par ![]() , où
, où![]() sont les points de l'intervalle fermé et borné
sont les points de l'intervalle fermé et borné ![]() en lesquels la fonction continue
en lesquels la fonction continue ![]() atteint son maximum et minimum. On utilise maintenant le fait qu'une fonction continue sur
atteint son maximum et minimum. On utilise maintenant le fait qu'une fonction continue sur ![]() y est uniformément continue
y est uniformément continue![]() , pour
, pour ![]() donné il existe
donné il existe ![]() (indépendant du point
(indépendant du point ![]() ) tel que
) tel que![]() . Donc, pour
. Donc, pour ![]() , on a
, on a ![]() . Ceci devient aussi petit que voulu, car on peut prendre des subdivisions équidistantes pour lesquelles
. Ceci devient aussi petit que voulu, car on peut prendre des subdivisions équidistantes pour lesquelles ![]() , il suffit donc de prendre
, il suffit donc de prendre ![]() assez petit.
assez petit.
Pour montrer qu'une fonction continue est uniformément continue sur un intervalle borné ![]() , on peut utiliser que l'ensemble des boules ouvertes
, on peut utiliser que l'ensemble des boules ouvertes ![]() telles que
telles que![]() , est un recouvrement ouvert de
, est un recouvrement ouvert de ![]() , dont on peut extraire un recouvrement fini d'après le théorème de Heine-Borel. Le minimum de ces
, dont on peut extraire un recouvrement fini d'après le théorème de Heine-Borel. Le minimum de ces ![]() correspond au
correspond au ![]() de l'uniforme continuité (au pire pour
de l'uniforme continuité (au pire pour ![]() au lieu de
au lieu de ![]() ).
).
(Pour une démonstration du théorème de Heine-Borel, voir ailleurs...)
Corollaire De même, une fonction (bornée!) continue sauf en un nombre fini de points, ou monotone sur chaque sous-intervalle d'une partition finie de ![]() , est Riemann-intégrable
, est Riemann-intégrable![]() . (On peut en effet utiliser l'additivité des sommes de Darboux
. (On peut en effet utiliser l'additivité des sommes de Darboux![]() ,
, ![]() pour
pour ![]() qui entraîne celle de
qui entraîne celle de ![]() et de même pour
et de même pour ![]() .)
.)
Remarque [fonction de Dirichlet] La fonction de Dirichlet,

n'est pas Riemann-intégrable, car on a
En effet, sur chaque
Remarque Le pas uniforme des subdivisions équidistantes simplifie beaucoup l'expression des sommes de Darboux (exercice!).
On peut montrer que pour ![]()
![]() , on a
, on a
 |
La réciproque est vraie si
Sommes de Riemann
Les sommes de Darboux ne sont pas très utiles pour le calcul effectif d'une intégrale, par exemple à l'aide d'un ordinateur, car il est en général assez difficile de trouver les inf et sup sur les sous-intervalles. On considère plutôt
 ou
ou 
Plus généralement:
Définition Si ![]() vérifie
vérifie ![]() , on appelle
, on appelle ![]() une subdivision pointée et
une subdivision pointée et

la somme de Riemann associée à la subdivision pointée

c'est de là que vient la notation
Théorème Si ![]() , alors les sommes de Riemann
, alors les sommes de Riemann![]()
![]() tendent vers
tendent vers ![]() , independamment du choix des
, independamment du choix des ![]() , lorsque la subdivision devient de plus en plus fine.
, lorsque la subdivision devient de plus en plus fine.
Démonstration Par définition, il est évident que ![]() . Soit
. Soit ![]() et
et ![]() tel que
tel que ![]() . Alors on a aussi
. Alors on a aussi![]() , quel que soit le choix des
, quel que soit le choix des ![]() , et a fortiori pour tout
, et a fortiori pour tout ![]() . D'où le résultat.
. D'où le résultat.
Si ![]() est continue,
est continue, ![]() atteint son minimum et maximum sur chaque
atteint son minimum et maximum sur chaque ![]() en un certain
en un certain ![]() et
et ![]() . On obtient donc les sommes de Darboux
. On obtient donc les sommes de Darboux![]() comme cas particulier des sommes de Riemann, en associant à chaque
comme cas particulier des sommes de Riemann, en associant à chaque ![]() des points
des points ![]() tels que
tels que ![]() .
.
En particulier, lorsque la fonction est monotone, par exemple croissante, sur un sous-intervalle ![]() , alors
, alors ![]() et
et ![]() . Les sommes de Riemann
. Les sommes de Riemann ![]() et
et ![]() données en début de ce paragraphe coïncident donc avec les sommes de Darboux inférieure et supérieure pour une fonction croissante.
données en début de ce paragraphe coïncident donc avec les sommes de Darboux inférieure et supérieure pour une fonction croissante.
Source : http://www.les-mathematiques.net/a/d/a/node2.php3#SECTION...
15:35 Publié dans Intégrale de Riemann | Lien permanent | Commentaires (1) | Tags : intégrale de riemann | | del.icio.us | | Digg | Facebook
05/01/2010
Cours de 6ème - quadrilatère
| ||
|

11:09 Publié dans Cours de 6ème - quadrilatère | Lien permanent | Commentaires (0) | Tags : cours de 6ème - quadrilatère | | del.icio.us | | Digg | Facebook
Cours de 6ème - Repérage dans le plan
 | Repérages dans le plan |
| Définitions et exemples : | |
 |
+2 et + 3 sont les coordonnées du point , Les coordonnées des autres points sont : B (4,2) ;C(-4,4) ;D(-1,3); E(-2,-2) et F(-3,-4) |
11:08 Publié dans Cours de 6ème - Repérage dans le plan | Lien permanent | Commentaires (0) | Tags : cours de 6ème - repérage dans le plan, 6ème, plan, collège | | del.icio.us | | Digg | Facebook
Cours de 6ème - Les nombres décimaux
| Les nombres décimaux |
DEFINITION
Un nombre décimal comporte une virgule . La partie entière est située à gauche
de la virgule . La partie décimale est située à droite de la virgule .
Exemple :
| 1 | , | 3 | 4 | 6 | 5 |
| Unités | Dixièmes | Centièmes | Millièmes | Dix-millièmes |
1,3465 peut se lire une unité trois dixièmes quatre centièmes six millièmes et cinq dix-millièmes
Remarque : Convention d'écriture :
On supprime les zéros inutiles .
Exemple :
0 , 750 = 750 millièmes = 75 centièmes = 0 , 75
11:07 Publié dans Cours de 6ème - Les nombres décimaux | Lien permanent | Commentaires (0) | Tags : cours de 6ème - les nombres décimaux | | del.icio.us | | Digg | Facebook
Cours de 6ème - Triangle
| | Triangle |
a) Triangle isocèle b) Triangle équilatéral c) Triangle rectangle |
11:06 Publié dans Cours de 6ème - Triangle | Lien permanent | Commentaires (0) | Tags : cours de 6ème - triangle | | del.icio.us | | Digg | Facebook
Cours de 6ème - Symétrie Axiale
Définition : Deux figures symétriques par rapport à une droite d sont superposables par
Propriété : Définition : Une figure possède un axe de symétrie, si elle est sa propre symétrique dans la symétrie par rapport à cet axe.
Définition : Deux points A et A' sont symétriques par rapport à une droite (d) signifie que (d) est la médiatrice du segment [AA'].
Propriété : Un point situé sur l'axe de symétrie (d) sera son propre symétrique.
La symétrie axiale conserve les longueurs : le symétrique d'un segment par rapport à une droite est un segment de même longueur ; et les angles :le symétrique d'un angle par rapport à une droite est un angle de même mesure.
|





11:03 Publié dans Cours de 6ème - Symétrie Axiale | Lien permanent | Commentaires (0) | Tags : cours de 6ème - symétrie axiale | | del.icio.us | | Digg | Facebook
Cours de 6ème - Fractions
Fractions
Définitions
| est une écriture fractionnaire du quotient de a par b. |
a est le numérateur.
b est le dénominateur.
Lorsque le numérateur et le dénominateur sont des nombres entiers, l'écriture fractionnaire est appelée fraction.Fractions égales
On ne change pas un nombre en écriture fractionnaire en multipliant ou en divisant son numérateur et son dénominateur par un même nombre non nul .Soient a , b et k trois entiers , alors :
Multiplier un nombre à une fraction :
Pour multiplier un nombre à une fraction , on mutiplie ce nombre au numérateur ensuite on divise le résultat obtenu par le dénominateur .
Source :
http://194.2.124.18/monbru/index.html

11:02 Publié dans Cours de 6ème - Fractions | Lien permanent | Commentaires (0) | Tags : cours de 6ème, fractions, collège | | del.icio.us | | Digg | Facebook
Cours de 6ème - Droites parallèles et droites perpendiculaires :
Droites parallèles et droites perpendiculaires :
- Définitions .
Deux droites sécantes sont deux droites qui ont un ( seul ) point commun. Sinon, elles sont parallèles. (d) et (d') sont deux droites parallèles .
(d) et (d') sont deux droites parallèles .
Deux droites perpendiculaires sont deux droites ( sécantes ) qui forment un angle droit.
 (d) et (d') sont deux droites perpendiculaires .
(d) et (d') sont deux droites perpendiculaires . - Propriétés .
Si deux droites sont perpendiculaires à une même troisième, alors elles sont parallèles.
 Les droites (d) et (d') sont perpendiculaires à la droite (d1), alors les droites (d) et (d') sont parallèles .
Les droites (d) et (d') sont perpendiculaires à la droite (d1), alors les droites (d) et (d') sont parallèles .
Si deux droites sont parallèles et si une troisième est perpendiculaire à l'une, alors elle est perpendiculaire à l'autre . Les droites (d) et (d') sont parallèles ,la droite (d1)est perpendiculaire à la droite (d) , alors les droites (d1) et (d') sont perpendiculaires .
Si deux droites sont parallèles à une même troisième, alors elles sont parallèles. Les droites (d1) et (d2) sont parallèles à la droite (d3) , alors (d1) et (d2) sont parallèles.
Les droites (d1) et (d2) sont parallèles à la droite (d3) , alors (d1) et (d2) sont parallèles.
10:55 Publié dans Droites parallèles et droites perpendiculaires : | Lien permanent | Commentaires (0) | Tags : cours de 6ème, droites parallèles et droites perpendiculaires :, collège, 6ème | | del.icio.us | | Digg | Facebook
Fractal Zoom Mandelbrot Corner
| ||
10:47 Publié dans Fractal Zoom Mandelbrot Corner | Lien permanent | Commentaires (0) | Tags : fractal zoom mandelbrot corner, mandelbrot | | del.icio.us | | Digg | Facebook
03/01/2010
Quelques informations sur les fractales
 |
| |

Quelques informations sur les fractales
 Retour à la page de présentation
Retour à la page de présentation
Avertissement : la lecture de cette page est inutile si les fractales vous sont familières. Elle est fortement déconseillée aux mathématiciens, à moins qu’ils soient très indulgents pour l’aspect élémentaire et les approximations de ces explications.
![]()
Euclide et les fractales | |
| Euclide aurait certainement horrifié s’il avait connu les fractales, comme l’ont été beaucoup de ses successeurs, beaucoup plus proches de nous, qui ne voyaient là que des monstres mathématiques dont il convenait de se détourner ! Et pourtant... On obtient une image fractale en partant d’un objet graphique auquel on applique une certaine transformation qui ajoute un élément de complexité, puis en appliquant la même transformation au nouvel objet ainsi obtenu, ce qui accroît encore sa complexité... et en recommençant à l’infini ce processus d’itération. Bien entendu toutes les itérations n’engendrent pas des fractales. Prenons un segment de droite et effaçons-en une moitié, puis appliquons au demi-segment résultant la même opération : il est évident que pour un nombre d’itérations infini la figure tend vers un point. Rien de très passionnant.
| |
|
| |
 En effet, imaginons qu’on « zoome » dans cette figure avec une loupe puis un microscope à des grossissements de plus en plus puissants. Quel que soit le grossissement on observera la même structure. On sera donc incapable, sur un détail, de décider quel est le grossissement auquel la poussière de Cantor aura été observée (dans l’illustration ci-dessus la résolution de l’écran limite l’observation des plus fins détails). En effet, imaginons qu’on « zoome » dans cette figure avec une loupe puis un microscope à des grossissements de plus en plus puissants. Quel que soit le grossissement on observera la même structure. On sera donc incapable, sur un détail, de décider quel est le grossissement auquel la poussière de Cantor aura été observée (dans l’illustration ci-dessus la résolution de l’écran limite l’observation des plus fins détails). Première propriété d’une image fractale : l’auto-similarité, ou invariance d’échelle.
| |
|
| |
| Légèrement plus spectaculaire est l’exemple de la « courbe » ou « flocon » de Koch. Cette « courbe » s’obtient en appliquant à chaque côté d’un triangle équilatéral une transformation un peu différente : on remplace le 1/3 central de chaque côté par 2 segments ayant la même longueur que celle qui a été prélevée. À la première itération on obtient une image proche d’une étoile de David, puis au fur et à mesure des itérations successives le résultat mime plus ou moins un flocon de neige. Là encore, à quelque grossissement qu’on examine la « courbe » on observera les mêmes détails... pour autant que le nombre d’itérations soit infini (ou, au moins, assez important).
| |
|
| |
| Ce type de courbe présente une particularité bien curieuse. La première intuition conduit à penser que, puisqu’on ajoute des détails de plus en plus petits au fur et à mesure des itérations successives, le périmètre de cette figure tend vers une valeur limite finie. En réalité, à la première itération la longueur l de chaque côté est remplacée par 4 l / 3 ; à la deuxième elle devient 16 l / 9... Autrement dit, à chaque itération la longueur est multipliée par 4 / 3, ce qui signifie que (contrairement à l’intuition première) la longueur d’une courbe de Koch tend vers l’infini pour un nombre d’itérations infini. Et pourtant cette courbe ne déborde à aucun moment des limites constituées à l’extérieur par le cercle circonscrit au triangle initial, et à l’intérieur par le cercle inscrit dans ce triangle ! Une autre propriété encore moins intuitive est relative à la dimension des objets fractals. Nous savons tous qu’un point est une figure de dimension 0 ; qu’une ligne droite est un objet de dimension 1 ; qu’une surface plane est un objet de dimension 2 ; qu’un volume est de dimension 3... qu’en est-il d’un objet fractal ? | |



Les nombres complexes et les fractales | |
| Il existe toute une série d’objets fractals curieux qu’il est possible de construire à partir d’opérations simples de la géométrie euclidienne, comme les précédents (l’image en tête de page est une variante du tamis de Sierpinski, après 4 itérations). Certains sont des figures planes, d’autres déploient leur structure dans l’espace. Mais si l’on applique le procédé d’itération à des formules même très simples, utilisant lesnombres complexes, on entre dans un monde fabuleux de formes étranges et d’une beauté parfois étonnante. Rappelons qu’un nombre complexe a la structure générale suivante :
| |
| z = x + yi | |
| où x et y sont des nombres réels et i est la racine carrée de -1 (opération qui était jugée impossible par les mathématiques anciennes, puisqu’avec les nombres réels un carré est toujours positif). x est la partie réelle du nombre et y est la partie imaginaire. On peut se demander comment on peut représenter graphiquement un fonction utilisant des nombres complexes puisqu’il n’est pas possible d’associer une image mentale concrète à un nombre aussi étrange que la racine carrée de -1. Le principe qui guide la réalisation de la plupart de ces images sur un ordinateur est en réalité très simple. Quand on gradue un axe de coordonnées on peut donner à chaque division de l’axe une valeur unité conventionnelle quelconque. Si l’on dit que la valeur qu’une division vaut i on aura d’un côté de l’origine la représentation des nombres i, 2i, 3i... et de l’autre côté -i, -2i, -3i... l’axe des x représente la partie réelle du résultat du calcul ; l’axe des y représente la partie imaginaire, et la luminosité ou la couleur de chaque point est fonction du nombre d’itérations nécessaires pour que le résultat réponde à une condition donnée. Prenons une expression aussi simple que
| |
|
| |
| c est un nombre complexe quelconque fixé au départ. On fait le calcul pour chacun des points z du plan complexe (chaque point a une coordonnée x réelle et une coordonnée y imaginaire). Seulement, petit détail, au lieu de faire le calcul une seule fois pour chaque point, on recommence en donnant à z la valeur z' trouvée dans le calcul précédent et l’on recommence encore en donnant à z la valeur z' trouvée par ce nouveau calcul... En bref on effectue un nombre d’itérations théoriquement infini lors du calcul de chacun des points, ce qui peut s’écrire
| |
|
| |
| en partant d’une valeur initiale z(0) égale aux coordonnées de chaque point du plan complexe. Il est intéressant de voir vers quelle valeur tend cette fonction pour chacun des points du plan complexe. On s’aperçoit que pour beaucoup de points (c’est-à-dire de valeurs initiales de z) la fonction diverge plus ou moins rapidement (la valeur de z' s’écarte de plus en plus de la valeur initiale). Au contraire pour certains points le résultat reste définitivement enfermé dans un intervalle limité : la fonction ne diverge pas, même pour un nombre infini d’itérations.
| |
|
partie réelle de c = -0.0519... partie imaginaire = 0.688... | |
| Dans certains cas l’ensemble de Julia est continu (ou, plus rigoureusement, connexe) comme ci-dessus, mais dans d’autres il est fragmenté (non connexe) comme ci-dessous.
| |
|
partie réelle de c = -0.577... partie imaginaire = 0.478... | |
| Les points pour lesquels la valeur de z diverge ne font pas partie de l’ensemble de Julia rempli : ils sont situés à l’extérieur. Mais on peut obtenir des informations complémentaires en leur affectant une luminosité ou une couleur fonction du nombre d’itérations nécessaires pour observer la divergence. En d’autres termes cette couleur est une mesure de la vitesse avec laquelle la fonction diverge pour ce point. Autour de l’ensemble proprement dit, coloré en noir ici, on observe une série d’auréoles dessinant des figures parfois très intéressantes (voir ci-dessus et ci-dessous).
| |
|
| |
| Si, au lieu de donner une valeur fixe et arbitraire à c on lui affecte pour tout point du plan complexe une valeur initiale c = z(0), on obtient un objet mathématique plus complexe appelé ensemble de Mandelbrot. l’ensemble de Mandelbrot est, là encore, l’objet noir au centre de l’image.
| |
|
Remarque : contrairement aux apparences l’ensemble de Mandelbrot est connexe, mais certains détails sont si ténus qu’ils ne sont pas visibles à la résolution de l’écran. | |
| Si l’explication précédente ne vous a pas parue claire, en voici une autre, strictement équivalente. Au lieu de calculer la fonction en donnant une valeur constante et arbitraire à c, considérons c comme une variable à laquelle nous attribuerons successivement les valeurs correspondant aux différents points du plan complexe (heureusement sur un écran d’ordinateur le nombre de points à calculer est limité par le nombre de pixels affichés). Pour chacune de ces valeurs itérons la fonction en partant de la valeurz(0)=(0,0) et colorons chaque point c en utilisant la même recette que pour les ensembles de Julia. Nous obtenons l’ensemble de Mandelbrot. Pourquoi les deux explications sont-elles équivalentes ? Parce qu’à la première itération la valeur de z étant nulle, la valeur de z(1) est égale à0+c, c’est-à-dire c. Relisez maintenant la première explication et choisissez celle que vous préférez. Bien entendu, s’il y a une infinité d’ensembles de Julia, il n’existe qu’un seul ensemble de Mandelbrot pour la fonction
| |
|
| |
| Il y a, évidemment, une relation entre cet ensemble et les ensembles de Julia : l’ensemble de Mandelbrot est l’ensemble de tous les points cpour lesquels l’ensemble de Julia correspondant est connexe. Autrement dit, quand on prend pour c une valeur en dehors de la surface noire on obtient un ensemble de Julia « brisé ». Les ensembles de Mandelbrot et de Julia sont des objets fractals et en zoomant sur leur bordure on peut y voir, quel que soit le grossissement, des structures toujours aussi complexes et auto-similaires. c’est ainsi que l’ensemble de Mandelbrot possède à sa périphérie une multitude de ramifications qui se dilatent localement en mini-ensembles de Mandelbrot qui, à leur tour... Tous ces détails sont auto-similaires, ce qui ne veut pas dire qu’ils soient rigoureusement identiques entre eux (contrairement aux fractales plus vues plus haut, engendrées par des opérations géométriques simples). La série d’image suivante montre des grossissements de plus en plus forts révélant des mini-ensembles de Mandelbrot à la périphérie de l’ensemble central. Toutes les images, sauf la dernière, ont été traitées en niveau de bleu pour simplifier la reconnaissance des formes. Dans chacune un petit rectangle montre les limites de l’image suivante. En cliquant sur chaque image on visualise une image de taille 800x600. Le facteur d’agrandissement entre la première et la dernière image de la série est de 3 200 000 fois.
| |
| Toutes les images peuvent être vues au format 800x600 | |
| La fonction qui engendre les ensembles de Julia et de Mandelbrot est l’exemple le plus simple qu’on puisse trouver. Pourtant l’ensemble de Mandelbrot est considéré par certains comme l’objet mathématique le plus complexe connu. Toutes ses propriétés n’ont d’ailleurs pas encore été démontrées. On a pu établir que la dimension de sa bordure est 2, ce qui est la plus grande dimension fractale possible pour une structure de surface nulle (mais curieusement on n’a pas encore démontré que cette surface est nulle, bien que ceci paraisse intuitivement évident :Douady, communication personnelle ; 1996). Beaucoup d’amateurs d’images fractales utilisent d’autres fonctions. Certaines ne sont que des modifications plus ou moins complexes des formules de Julia et Mandelbrot ; d’autres sont totalement différentes. Le programme Fractint et d’autres programmes plus récents permettent de tester sans problème pratiquement toutes les fonctions nouvelles qu’on peut imaginer. Il reste un dernier détail : comment tester si la fonction diverge pour un point donné du plan complexe ? Je me limiterai encore aux ensembles de Julia et de Mandelbrot, mais le principe est applicable à beaucoup d’autres fonctions. Il consiste à vérifier que le module de zreste inférieur ou égal à une valeur de référence qui, pour les deux ensembles choisis comme exemple, est 2 (sur ce point nous ferons confiance aux mathématiciens). c’est la « valeur d’échappement » (bailout value en anglais).
| |
|
| |
| (remarquez que pour la vitesse du calcul il est plus facile de vérifier que le carré du module est <= 4, astuce utilisée par Fractint). | |





![]()
| Informations théoriques sur d’autres serveurs. |
| ||
| Retour à la page de présentation | ||
| Mon album de fractales | |||
| Dernière mise à jour : 02/10/03
| |||
11:26 Publié dans Quelques informations sur les fractales | Lien permanent | Commentaires (0) | Tags : quelques informations sur les fractales | | del.icio.us | | Digg | Facebook
Cours de tests paramétriques
Cours de tests paramétriques
Descriptif du cours
| Auteurs : | Peggy Cénac, Florence Muri-Majoube | ||||
| Domaine : | Mathématiques :: Statistique | ||||
| Niveau : | Licence | Langue : | Français | ||
| Description : | Ce cours introduit les concepts nécessaires pour développer et appliquer les tests paramétriques. |
| Prérequis : | |
| Mots clefs : | test ; paramétrique ; comparaison ; moyenne ; variance ; intervalle ; de ; confiance ; niveau ; puissance |
| Commentaire : |
Documents associés
| Par Peggy Cénac, Florence Muri-Majoube Source : http://www.librecours.org/cgi-bin/course?callback=info&am... |

11:02 Publié dans Cours de tests paramétriques | Lien permanent | Commentaires (0) | Tags : cours de tests paramétriques | | del.icio.us | | Digg | Facebook
La théorie des groupes et résolutions des équations algébriques
La théorie des groupes et résolutions des équations algébriques
Descriptif du cours
| Auteurs : | Serge Hublau | ||||
| Domaine : | Mathématiques :: Histoire des mathématiques | ||||
| Niveau : | Licence | Langue : | Français | ||
| Description : | Vulgarisation de la théorie des groupes, de la théorie de Galois et de leurs applications à la résolution par radicaux des équations polynomiales insistant sur l'aspect historique des fondements de la théorie de Galois |
| Prérequis : | |
| Mots clefs : | |
| Commentaire : |
Documents associés
| Par Serge Hublau Vulgarisation de la théorie des groupes, de la théorie de Galois et de leurs applications à la résolution par radicau...  Date d'envoi : 07-Dec-2004 17:04 Date d'envoi : 07-Dec-2004 17:04 | PDF (2.20Mo) PS (3.19Mo) |
Tables des matières
| Du nombre au groupe Source : http://www.librecours.org/cgi-bin/course?callback=info&am... |
11:00 Publié dans La théorie des groupes et résolutions des équation | Lien permanent | Commentaires (0) | Tags : la théorie des groupes et résolutions des équations algébriques | | del.icio.us | | Digg | Facebook
L'histoire des logarithmes
L'histoire des logarithmes
Descriptif du cours
| Auteurs : | Simon Trompler | ||||
| Domaine : | Mathématiques :: Histoire des mathématiques | ||||
| Niveau : | Licence | Langue : | Français | ||
| Description : | Les logarithmes: histoire de leur développement. |
| Prérequis : | |
| Mots clefs : | histoire ; logarithme ; log |
| Commentaire : |
Documents associés
| Par Simon Trompler Les logarithmes: histoire de leur développement. Date d'envoi : 12-Jan-2004 14:45 | PDF (265.25ko) PS (768.18ko) |
Tables des matières
| Première partie: Les logarithmes. Histoire de leur développement
Source : http://www.librecours.org/cgi-bin/course?callback=info&am... |
10:52 Publié dans L'histoire des logarithmes | Lien permanent | Commentaires (0) | Tags : l'histoire des logarithmes | | del.icio.us | | Digg | Facebook
Preuves formelles en Coq
Preuves formelles en Coq
par Loïc PottierDescription :
Cours d'option en DEA de mathématiques, université de Nice-Sophia Antipolis, janvier 2003. Ce cours est inspiré du cours de DEA de Gilles Dowek, et du cours de DEA de Christine Paulin-Mohring et Benjamin Werner (DEA de programmation SPL, Paris).Télécharger :
PDF (690.34ko)PS (158.35ko)

Tables des matières
| Le langage de Coq Source : http://www.librecours.org/cgi-bin/course?callback=info&am... |
Modérateurs
Dimitri Ara, Romain Théret
Contact : logique AT librecours.org
Source : http://www.librecours.org/cgi-bin/domain?callback=info&am...
10:51 Publié dans Preuves formelles en Coq | Lien permanent | Commentaires (0) | Tags : preuves formelles en coq | | del.icio.us | | Digg | Facebook