





























08/03/2011
Maths 5ème pour les nuls Yann Gélébart Scolaire / Universitaire (broché). Paru en 02/2009

19:15 Publié dans 5ème | Lien permanent | Commentaires (0) |  |
|  del.icio.us |
del.icio.us |  |
|  Digg |
Digg |  Facebook
Facebook
Les années de Mathématiques 6ème 5ème 4ème 3ème Collectif Scolaire / Universitaire (broché). Paru en 04/2009

19:14 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Maths 3ème Collectif Scolaire / Universitaire (broché). Paru en 06/2010


19:13 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Mathématiques 4ème Collectif Scolaire / Universitaire (broché). Paru en 09/2007

19:11 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Sujets du brevet non-corrigés mathématiques, Edition 2005 Collectif Scolaire / Universitaire (broché). Paru en 08/2004

19:10 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Le guide ABC Brevet Maths 3ème , Révisions Collectif Scolaire / Universitaire (broché). Paru en 06/2010

19:02 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Oxford Cahier Objectif Brevet Maths Oxford 24x32 96 pages quadrillés Q5x5mm Cahiers petits carreaux (5/5)

19:01 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Algèbre générale , Rappels de cours, questions de réflexion, exercices d'entraînement Anne Denmat, François Héaulme, Daniel Fredon Etude (broché). Paru en 06/2000

18:59 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
cédérom PC M Comme Maths - Algèbre 5ème Editeur : Homeworktv France

18:58 Publié dans 5ème | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
100 énigmes pour réussir en maths, 10-11 ans Jean-Luc Caron, Jacques De Vardo Scolaire / Universitaire (broché). Paru en 03/2010

18:57 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
100 jeux-tests pour être fort en calcul, 9-10 ans Collectif Scolaire / Universitaire (broché). Paru en 09/2010

18:56 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
CRPE mathématiques , Fiches Eric Greff, André Mul Scolaire / Universitaire (broché). Paru en 06/2010

18:55 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
14/02/2011
Les trois livres de porismes d'Euclide, rétablis pour la première fois, d ... Par Euclid,Pappus (of Alexandria.)
21:10 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Pappus of Alexandria: Book 4 of the Collection: Edited With ..., Livre 4 Par Heike Sefrin-Weis
21:07 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
SPIRALE CONIQUE DE PAPPUS Conical spiral of Pappus, Pappussche konische Spirale
SPIRALE CONIQUE DE PAPPUS
Conical spiral of Pappus, Pappussche konische Spirale
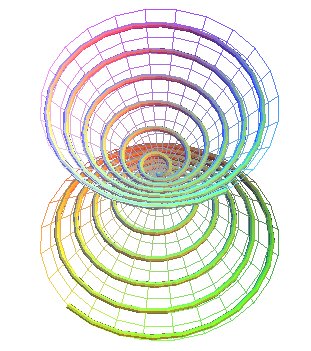
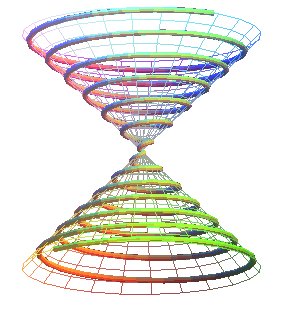
| Courbe étudiée par Pappus, Pascal en 1779, et Chasles en 1843. Pappus : mathématicien d'Alexandrie (IVe siècle avant J.C.). |
La spirale conique de Pappus est la trajectoire d'un point se déplaçant uniformément sur une droite passant par un point O, cette droite tournant uniformément autour d'un axe Oz en conservant un angle a avec Oz.
Elle est donc intersection du cône de révolution (C) : ![]() avec l’hélicoïde droit :
avec l’hélicoïde droit : ![]() .
.
Si l’on développe le cône (C) sur un plan, le point M devenant le point de coordonnées polaires ![]() , la spirale de Pappus devient la spirale d’Archimède :
, la spirale de Pappus devient la spirale d’Archimède : 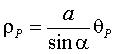 , autrement dit, la spirale de Pappus est un enroulement conique de spirale d’Archimède.
, autrement dit, la spirale de Pappus est un enroulement conique de spirale d’Archimède.
La projection sur xOy est aussi une spirale d’Archimède, qui coïncide avec la spirale de Pappus pour 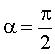 .
.
La spirale de Pappus est la podaire de l'hélice circulaire par rapport à un point de son axe, c'est à dire le lieu des projetés de ce point sur les plans osculateurs à l'hélice.
La trace sur xOy de sa tangente est la spirale de Galilée : ![]() .
.
La trace sur xOy de la droite orthogonale à la courbe et incluse dans le plan tangent au cône est le cercle de centre O et de rayon 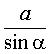 .
.
Il ne faut pas la confondre avec l'hélice conique : la spirale conique de Pappus est à la spirale d'Archimède, ce que l'hélice conique est à la spirale logarithmique !
 Gravure de wentzel Jamnitzer Perspectiva corporum regularium |
 |
![]()
Source : http://www.mathcurve.com/courbes3d/spiraleconic/pappus.sh...
Équation sphérique : 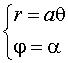 . . Équation cylindrique : 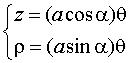 . . Paramétrisation cartésienne : 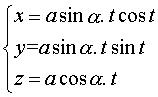 . . |
21:05 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Pappus d'Alexandrie
Pappus d'Alexandrie vécut au ive siècle après J.C. Actif vers 300, il est un des plus importants mathématiciens de la Grèce antique, connu pour son ouvrage Synagoge (traduit en français sous le titre de « Collection mathématique»). Il naquit à Alexandrie en Égypte. Bien que très peu de choses sur sa vie soient connues, les écrits nous suggèrent qu'il fut un précepteur. Son principal ouvrage est connu sous le nom Synagoge (vers 340 de notre ère). Il comprend au moins huit volumes, le reste a été perdu, laCollection couvre un grand nombre de rubriques mathématiques, incluant la géométrie, les mathématiques récréatives, la construction d'un cube du double d'un cube donné, de polygones et de polyèdres. C'est par Pappus que nous sont parvenues les sources les plus riches des mathématiques grecques, et que nous connaissons les titres et le contenu des grands traités de l'époque hellénistique (la Petite Astronomie, le Trésor de l'Analyse). Il introduisit la notion de rapport anharmonique. En géométrie, son nom est resté attaché de nos jours au théorème de Pappus. Pappus, au livre VII de la Collection mathématique, nous fait connaître ce que les Anciens entendaient par les termes d'analyse, de porisme et desynthèse : il s'agissait d'un corpus de méthodes permettant de résoudre à la règle et au compas des problèmes de lieux géométriques. Pappus cite plusieurs traités (aujourd'hui presque tous perdus ; les titres en latin sont dus à Commandino) qui traitent du « lieu résolu » (ὁ Τόποϛ ἀναλυόμενοϛ): Le propos de l'Analyse des Anciens, tel que l'expose Pappus dans le livre VII de sa « Collection Mathématique », était de trouver une construction à la règle et au compas d'un lieu géométrique donné, ou du moins d'inventorier les cas où une telle construction était possible. Malheureusement, Pappus n'a transmis que des résumés des livres qu'il cite, de sorte que l'étendue et la portée des méthodes de l'analyse a fait l'objet de multiples gloses du XVIe au XVIIIe siècle. S'appuyant sur les indices donnés par Pappus et leurs spéculations personnelles, une pléïade de mathématiciens fameux se sont essayés à reconstruire les traités perdus dans leur ordre original. Voir aussi la bibliographie des Irem (France) et celle du Complete Dictionary of Scientific Biography.Pappus d'Alexandrie
![]() Pour l’article homonyme, voir Pappus.
Pour l’article homonyme, voir Pappus. Pappus et l'Analyse des Anciens[modifier]
Bibliographie[modifier]
Œuvres de Pappus[modifier]
Études sur Pappus[modifier]

Sommaire[masquer] |
21:02 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Multiplicateur de Lagrange
![]() Pour les articles homonymes, voir Théorème de Lagrange.
Pour les articles homonymes, voir Théorème de Lagrange.
Le multiplicateur de Lagrange est une méthode permettant de trouver les points stationnaires (maximum, minimum...) d'une fonctiondérivable d'une ou plusieurs variables, sous contraintes.
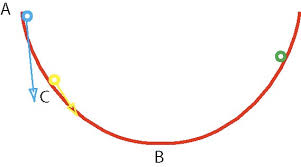
On cherche à trouver l'extremum, un minimum ou un maximum, d'une fonction φ de n variables à valeurs dans les nombres réels, ou encore d'un espace euclidien de dimension n, parmi les points respectant une contrainte, de type ψ(x) = 0 où ψ est une fonction du même ensemble de départ que φ. La fonction ψ est à valeurs dans un espace euclidien de dimension m. Elle peut encore être vue comme m fonctions à valeurs réelles, décrivant m contraintes. Si l'espace euclidien est de dimension 2 et si la fonction ψ est à valeurs dans R, correspondant à une contrainte mono-dimensionnelle, la situation s'illustre par une figure analogue à celle de droite. La question revient à rechercher le point situé le plus haut, c'est-à-dire le maximum de φ, dans l'ensemble des points rouges, c'est-à-dire ceux qui vérifient la contrainte.

La méthode des multiplicateurs de Lagrange permet de trouver un optimum, sur la figure le point le plus élevé possible, tout en satisfaisant une contrainte, sur la figure un point de la ligne rouge.
Le théorème clé se conçoit aisément dans l'exemple de dimension 2. Le point recherché est celui où la courbe rouge ne monte ni ne descend. En termes plus techniques, cela correspond à un point où la différentielle de ψ possède un noyau orthogonal au gradient de φ en ce point. Le multiplicateur de Lagrange est une méthode offrant une condition nécessaire. Les fonctions φ et ψ sont différentiables et leurs différentielles continues, on parle de fonction de classe C1. On considère λ un vecteur pris dans l'ensemble d'arrivée de ψ et la fonction L définie par :
L'opérateur représenté par un point est le produit scalaire. Si x0 est une solution recherchée, il existe un vecteur λ0 tel que la fonction L admet une différentielle nulle au point (x0, λ0). Les coordonnées du vecteur λ0 sont appelées multiplicateurs de Lagrange. Cette technique permet de passer d'une question d'optimisation sous contrainte à une optimisation sans contrainte, celle de la fonction L, dans un espace de dimension n+ m.
La méthode se généralise aux espaces fonctionnels. Un exemple est donnée par la question de la chaînette, qui revient à rechercher la position que prend au repos, une chaînette attachée à ses deux extrémités. L'optimisation correspond à la position offrant un potentiel minimal, la contrainte est donnée par la position des extrémités et la longueur de la chaînette, supposée fixe. Cette méthode permet de trouver des plus courts chemins sous contrainte, ou encore des géodésiques. Le principe de Fermat ou celui de moindre action permet de résoudre de nombreuses questions à l'aide de cette méthode.
Hugh Everett généralise la méthode aux fonctions non-dérivables, souvent choisies convexes. Pour une résolution effective, il devient nécessaire de disposer d'un algorithme déterminant l'optimum (ou les optima) d'une fonction. Dans le cas non dérivable, on utilise souvent uneheuristique adéquate.
Sommaire:
1. Dimension finie
2. Espace fonctionnel
3. Voir aussi
1. Dimension finie
1. 1. Exemple introductif

La nappe correspond à la surface du cylindre, la courbe bleue aux points de volume égal à v0, choisi dans la représentation égal à 1.
Soit v0 un nombre strictement positif, l'objectif est de trouver la portion de cylindre de rayon r et de hauteur h de surface minimale et de volume v0. Pour cela on définit deux fonctions, v et s qui à (r, h) associent respectivement le volume et la surface de la portion de cylindre. On dispose des égalités :
La figure de droite représente la fonction s, qui à r et h associe la surface. La ligne bleue correspond aux points de volume égal à 1, l'objectif est de trouver le point bleu, de plus petite surface pour un volume égal à 1.
On définit une fonction c et L de la manière suivante :
La méthode de Lagrange consiste à rechercher un point tel que la différentielle de L soit nulle. Sur un tel point, la dérivée partielle en λ est nulle, ce qui signifie que la fonction c est nulle, ou encore que la contrainte est respectée. Si l'on identifie s avec son approximation linéaire tangente, son comportement sur la contrainte, aussi identifiée à son approximation linéaire tangente est aussi nécessairement nulle. Ce comportement est illustré par la droite en vert sur la figure. Le long de cette droite, la fonction c est nulle, à l'ordre 1, la fonction s l'est alors nécessairement.
Il suffit, en conséquence, de calculer la différentielle de L, et plus précisément ses trois dérivées partielles, pour l'exemple choisi :
On trouve les valeurs suivantes :
1. 2. Deuxième exemple : l'isopérimétrie du triangle
L'exemple précédent possède l'avantage d'une représentation graphique simple, guidant l'intuition. En revanche, il est trop simple pour que la méthode du multiplicateur de Lagrange soit la meilleure dans ce cas. En effet, on peut aussi calculer la valeur de h pour que l'aire de la frontière soit égale à v0, on trouve :
Il devient possible d'exprimer le volume du cylindre d'aire égale à v0 en fonction de r et le calcul revient à trouver le minimum d'une fonction de R dans R.
Pour se convaincre de la pertinence de la méthode, on peut rechercher le triangle d'aire maximale et de périmètre p, choisi strictement positif. Si (x, y, z) est le triplet des longueurs des côtés du triangle, son aire A est égale à :
Il est plus simple de maximiser la fonction φ qui associe le quart du carré de A, la contrainte est donnée par la fonction ψ qui associe au triangle la différence du périmètre et de p :
Un triangle n'est défini, pour un couple (x, y, z), que si les trois coordonnées sont positives et si la somme de deux coordonnées est supérieure à la troisième. Soit D cet ensemble de points, sur la frontière de D, la fonction φ est nulle. On cherche un point de l'intérieur de D tel que φ soit maximal dans l'ensemble des points d'image par ψ nulle. Comme l'intersection de l'image réciproque de 0 par ψ et de D est un compact, il existe au moins un maximum. On définit comme dans l'exemple précédent la fonction L par :
Si (a, b, c) est un triangle de périmètre p et d'aire maximale, il existe une valeur λ0 telle que la différentielle de L au point (a, b, c, λ0) soit nulle. Un calcul de dérivée partielle montre que ce quadruplet est solution du système d'équations :
On en déduit que a, b et c sont tous racines de l'équation :
Si les trois valeurs sont distinctes, elles correspondent aux trois racines de l'équation (1), leur somme est égale au coefficient de degré 2, c'est-à-dire à 0. Un tel point ne peut être dans l'intérieur de D car il est soit égal au triplet nul, soit contient une coordonnée strictement négative. On en conclut qu'au moins deux coordonnées sont égales, par exemple b et c. On peut alors ajouter une cinquième équation aux quatre que fournissent le calcul des dérivées partielles : y = z. En remplaçant z par y dans la première et deuxième équation, on obtient :
On trouve trois cas : x = 0 correspond à un point de la frontière de D et c'est un minimum de φ, x = y correspond au triangle équilatéral et x = -2.y est un cas impossible car a est nécessairement strictement positif. L'unique solution est le triangle équilatéral de côté p/3 car a = b = c et la somme des trois longueurs est égale à p.
Remarque : L'objectif est ici d'illustrer la méthode du multiplicateur de Lagrange, on a trouvé le maximum d'une fonction φ dans l'intérieur deD, sous la contrainte définie par ψ. Si l'objectif est uniquement de résoudre le problème isopérimétrique pour le triangle, une solution plus simple est donnée dans l'article sur l'isopérimétrie.
1. 3. Notations et interprétation géométrique
Soit E et F deux espaces vectoriels réels de dimensions respectives n et m avec n plus grand que m. Soit φ une fonction de E dans , que l'on cherche à optimiser. On cherche un point a tel que φ(a) soit le plus petit possible. Soit ψ une fonction de E dans F, définissant la contrainte. L'ensemble sur lequel on travaille est G, correspondant aux points x tel que ψ(x) = 0.
Si (e1, ..., en) est une base de E, chaque point x de E s'exprime comme une combinaison linéaire des éléments de la base :
Cette remarque permet de voir les fonctions φ et ψ de deux manières. Elles peuvent être vues comme des fonctions d'une unique variable x deE, ce qui rend l'écriture plus concise et favorise une compréhension plus simple, mais plus abstraite des mécanismes en jeu. Les applications peuvent aussi être vues comme fonctions de n variables x1, ..., xn, ce qui présente une rédaction plus lourde mais plus aisée pour les calculs effectifs. L'espace F est de dimension m, si (f1, ..., fm) est une base de F, la fonction ψ peut aussi être vue comme m fonctions de n variables :
L'ensemble G peut être vu comme une unique contrainte exprimée par une fonction à valeurs dans F ou encore comme m contraintes exprimées par les égalités ψj(x) = 0, à valeurs dans R.

Un corollaire du théorème de Rolle indique que l'optimum est atteint en un point de différentielle nulle.

Le fondement théorique de la méthode du multiplicateur de Lagrange peut être vu comme analogue au théorème de Rolle.
Les fonctions φ et ψ sont de classe C1, ce qui signifie qu'elles sont différentiables, autrement dit elles admettent chacune une application linéaire tangente en chaque point. Le terme C1 signifie aussi que les applications qui, à un point associent les différentielles, soit de φ soit de ψ sont continues.
L'optimum recherché vérifie une propriété analogue à celle du théorème de Rolle. Un corollaire de ce théorème, illustré à gauche, indique que l'optimum, un maximum ou un minimum, s'il se situe dans l'intervalle ouvert ]a, b[, possède une tangente horizontale, ce qui signifie encore que sa différentielle est nulle. C'est un résultat de cette nature qui est recherché. On peut le visualiser sur la figure de droite, si n et m sont respectivement égaux à 2 et à 1. On représente φ (noté f sur la figure de droite) en bleu par ses courbes de niveau, comme les géographes. Les flèches représentent le gradient de la fonction φ. La différentielle de φ est une application linéaire de E dans R, c'est-à-dire une forme duale. Il est d'usage de considérer E comme un espace euclidien, de choisir la base de E orthonormale et d'identifier la différentielle avec le vecteur de E qui représente la forme duale. Dans ce cas, l'approximation linéaire tangente s'écrit :
La lettre o désigne un petit o selon la notation de Landau et le point entre le gradient de φ et h symbolise le produit scalaire. Le vecteur gradient est orthogonal à la courbe de niveau, dans le sens des valeurs croissantes de φ et de norme proportionnelle à la vitesse d'accroissement de φ dans cette direction. La contrainte vérifie une propriété analogue puisqu'elle est aussi différentiable. L'ensemble étudié est celui des valeurs x tel que ψ(x) est nul. Si x0 est élément de G, les points voisins de x0 dans G ont aussi une image nulle par ψ, autrement dit, l'espace tangent à G au point x0 est formé par les accroissements h de x0 qui ont une image par la différentielle de ψ nulle. La direction de l'espace tangent est le noyau de l'application différentielle de ψ. Une analyse par les fonctions coordonnées ψi exprime ce résultat en indiquant que l'espace tangent est l'intersection des hyperplans orthogonaux des gradients de ψi.
Une analyse au point optimal x0 recherché indique, en approximation du premier ordre, qu'un déplacement h dans la direction de l'espace tangent à G ne peut pas accroître la valeur de φ. Ceci signifie que le déplacement h est nécessairement orthogonal au gradient de φ en x0. C'est ainsi que se traduit le théorème de Rolle, dans ce contexte. Géométriquement, cela signifie que la courbe de niveau bleue et la ligne rouge sont tangentes au point recherché. Analytiquement cela se traduit par le fait que le noyau de la différentielle de ψ en x0 est orthogonal au gradient de φ en ce point.
1. 4. Théorèmes
Le problème à résoudre est de trouver le minimum suivant :
Les fonctions φ et ψ ne sont pas nécessairement définies sur tout E mais au moins sur des ouverts de E. De plus, le domaine de définition de φ possède une intersection non vide avec G.
La méthode des multiplicateurs de Lagrange se fonde sur un théorème.
Théorème du multiplicateur de Lagrange — Si le point x0 est un extremum local de φ dans l'ensemble G, alors le noyau de la différentielle de ψ au point x0 est orthogonal au gradient de φ en ce point. [1]
Un corollaire met en évidence le multiplicateur. Pour cela, il est nécessaire d'équiper F du produit scalaire tel que sa base soit orthonormale, le symbole t signifie la transposée d'une l'application linéaire, elle définit une application du dual de F, ici identifié à F dans le dual de E, encore identifié à E :
Corollaire 1 — Si le point x0 est un extremum local de φ dans l'ensemble G et si la différentielle de ψ au point x0 est surjective, il existe un vecteur λ0 de F tel que la somme de l'image de λ0 par la transposée de la différentielle de ψ au point x0 et du gradient de φ en ce point soit nulle :
Sous forme de coordonnées, on obtient :
Un deuxième corollaire est plus pragmatique, car il offre une méthode effective pour déterminer l'extremum. Il correspond à la méthode utilisée dans l'exemple introductif.
Corollaire 2 — Si le point x0 est un extremum local de φ dans l'ensemble G et si la différentielle de ψ au point x0 est surjective, alors il existe un vecteur λ0 de F tel que la fonction L de ExF dans R admet un gradient nul en (x0, λ0) : [2]
Ces théorèmes possèdent quelques faiblesses, de même nature que celle du théorème de Rolle. La condition est nécessaire, mais pas suffisante. Un point de dérivée nulle pour Rolle ou vérifiant les hypothèses du théorème du multiplicateur de Lagrange n'est pas nécessairement un maximum ou un minimum. Ensuite, même si ce point est un extremum, il n'est que local. Si une solution x0 est trouvée, rien n'indique que cet extremum local est le meilleur. L'approximation linéaire ne précise pas si cet optimum est un maximum ou un minimum. Enfin, comme pour le cas du théorème de Rolle, si les domaines de définition ne sont pas ouverts, il est possible qu'un point frontière soit un optimum qui ne vérifie pas le théorème. Ainsi, sur la figure de gauche, f(a) et f(b) sont des minima, mais la dérivée n'est nulle ni en a ni en b.
1. 5. Écriture du problème
Si l'écriture condensée permet de mieux comprendre la structure du théorème, les notations développées sont plus utiles pour une résolution effective. Dans la pratique, on considère souvent une fonction φ de Rn dans R et m fonctions ψj, avec j variant de 1 à m, aussi de Rn dans R. L'entier m est nécessairement plus petit que n pour pouvoir appliquer les théorèmes du paragraphe précédent. On cherche à trouver un n-uplet (a1, ..., an) tel que :
Pour cela, on définit la fonction L de Rn+m dans R par :
Le deuxième corollaire indique que résoudre les équations suivantes offrent sur condition nécessaire pour élucider le problème d'optimisation(1). Le n-uplet (a1, ..., an) est une solution de (1) seulement s'il existe un m-uplet (α1,...,αm) tel que le n+m-uplet (a1, ..., an, α1,...,αm) soit solution des n + m équations :
Cette méthode peut être généralisée aux problèmes d'optimisation incluant des contraintes d'inégalités (ou non linéaires) en utilisant lesconditions de Kuhn-Tucker. Mais également sur des fonctions discrètes à maximiser ou minimiser sous contraintes, moyennant un changement d'interprétation, en utilisant la méthode des multiplicateurs d'Everett (ou de Lagrange généralisés), plus volontiers appelée méthode des pénalités.
1. 6. Application : inégalité arithmético-géométrique
Article détaillé : Inégalité arithmético-géométrique.
La méthode du multiplicateur de Lagrange permet de démontrer l'inégalité arithmético-géométrique [5] . On définit les applications φ et ψ de dans
par :
On remarque que l'ensemble G, composé des n-uplets de coordonnées positives et de somme égale à est un compact de
. Sur ce compact la fonction φ est continue, elle admet nécessairement un maximum. Les deux fonctions φ et ψ sont bien de classe
, il est donc possible d'utiliser le multiplicateur de Lagrange pour trouver ce maximum. Pour cela, on considère la fonction L :
Une solution vérifie les équations :
On en déduit l'existence d'une unique solution, obtenue pour tous les égaux à
et λ égal à
. Ce qui s'exprime, en remplaçant s par sa valeur :
La moyenne géométrique est inférieure à la moyenne arithmétique, l'égalité n'ayant lieu que si les sont tous égaux.
Le multiplicateur de Lagrange offre une démonstration alternative de l'inégalité arithmético-géométrique.
2. Espace fonctionnel
2. 1. Exemple introductif : La chaînette
Article détaillé : Chaînette.

Le Viaduc de Garabit possède une arche dont la géométrie est celle d'une chaînette.
Il existe un autre contexte, qui fait appel au multiplicateur de Lagrange. Considérons une chaînette soumis à la gravité et recherchons son équilibre statique. La chaînette est de longueur a et l'on suppose qu'elle est accrochée à deux points d'abscisses -t0 et t0 et d'ordonnée nulle en ces deux points. Si son ordonnée est notée x, elle suit une courbe y=x(t) sur l'intervalle [-t0, t0], dont on se propose de calculer l'équation.
Dire qu'elle est à l'équilibre revient à dire que son potentiel Φ est minimal, où :
Ici, α désigne une constante physique, en l'occurrence le produit de g la gravitation terrestre, par la densité linéaire de la chaînette, supposée constante. La formule donnant la longueur d'un arc en fonction d'un paramétrage est donnée dans l'article Longueur d'un arc.
La chaînette n'est pas supposée être élastique, elle vérifie donc la contrainte Ψ, indiquant que sa longueur l0 n'est pas modifiée :
Si C1K(I) désigne l'ensemble des fonctions de [-t0, t0] dans R, dérivables et de dérivées continues, nulles en -t0 et t0, le problème revient à rechercher la fonction x0 telle que :
La similitude avec la situation précédente est flagrante. Pour pouvoir appliquer des multiplicateurs de Lagrange, il faut donner un sens au gradient de Φ et Ψ. Dans le cas où il existe deux fonctions de classe C2 de R3 dans R, notées φ et ψ telles que :
L'équation d'Euler-Lagrange affirme que :
Dans le cas particulier où les fonctions φ et ψ sont des fonctions de deux variables et ne dépendent pas de t, on obtient la formulation de Beltrami (cf l'article Équation d'Euler-Lagrange):
Dire que les deux gradients sont colinéaires revient à dire qu'il existe un réel λ, le multiplicateur de Lagrange, tel que :
La résolution de cette équation différentielle est une chaînette. La méthode du multiplicateur de Lagrange permet bien de résoudre la question posée [6] .
2. 2. Espace de Sobolev
Article détaillé : Espace de Sobolev.
L'exemple précédent montre que le contexte de l'équation d'Euler-Lagrange n'est pas loin de celui du multiplicateur de Lagrange. Si l'ensemble de départ de la fonction x(t) recherchée est un intervalle I ouvert et borné de R et l'ensemble d'arrivée E l'espace vectoriel euclidien, la généralisation est relativement aisée.
On suppose l'existence d'une fonction Φ à minimiser, son ensemble de départ est un espace fonctionnel, c'est-à-dire un espace vectoriel de fonctions, de I dans E et son ensemble d'arrivée R. La fonction Φ est construite de la manière suivante :
Le point sur le x indique la fonction gradient, qui à t associe le gradient de x au point t.
La fonction φ est une fonction de RxE2 dans R de classe C2. L'optimisation est sous contrainte, donnée sous une forme analogue à la précédente. On suppose l'existence d'une fonction Ψ de RxE2 dans F, un espace euclidien. La fonction Ψ est encore définie à l'aide d'une fonction ψ de classe C2 de IxE2, mais cette fois dans F un espace euclidien:
L'ensemble G est composée de fonctions deux fois dérivables de I dans E et dont l'image par Ψ est nulle. On suppose de plus que les valeurs des fonctions de G aux bornes de I sont fixes et, quitte à opérer une translation, on peut toujours supposer, sans perte de généralités, que ces fonctions sont nulles aux bornes de I.
La seule tâche un peu délicate est de définir l'espace vectoriel W2,2(I,E) sur lequel opèrent Φ et Ψ. Pour définir un équivalent de gradient, cet espace comporte nécessairement un produit scalaire. Si l'on souhaite établir des théorèmes équivalents aux précédents les fonctions dérivées et dérivées seconde sont définies et l'espace est complet. Un espace munis d'un produit scalaire et complet est un Hilbert. Sa géométrie est, de fait, suffisamment riche pour étendre les résultats précédents.
On note D l'espace des fonctions de I, à valeur dans E, de classe et à support compact et D* son dual topologique. L'espaceD est muni de la norme de la borne supérieure et l'espace D* est celui des distributions. Ce premier couple n'est pas encore satisfaisant car D est trop petit et D* trop gros pour permettre de définir un bon produit scalaire, à l'origine d'une géométrie aussi simple que celle d'un Hilbert.
L'espace D* contient le Hilbert des fonctions de carrés intégrables L2(I,E). En effet une fonction f de L2(I,E) agit sur D par le produit scalaire <.,.>Ldéfini par l'intégrale de Lebesgue :
C'est dans L2(I,E) que nous cherchons le bon espace. Dans cet espace, l'intégration par parties permet de définir la dérivée de la fonction f de L2(I). Comme g est à support compact et que I est ouvert, aux bornes de I, la fonction g est nulle. Si f est dérivable au sens classique du terme, on bénéficie des égalités :
Si la distribution dérivée de f est encore d'un élément de L2(I,E), on dit qu'elle est dérivable au sens de Sobolev. Si cette dérivée est encore dérivable au sens précédent, on dit qu'elle est deux fois dérivables au sens de Sobolev. On note W2,2(I,E) le sous-espace deL2(I,E) équipé du produit scalaire suivant <.,.>W :
Les intégrales sont bien définies car elles correspondent au produit de deux élément de L2(I,E), il est ensuite simple de vérifier que l'espace est bien complet [7] . Enfin, si f est une fonction dérivable au sens des distributions, il existe un représentant de f continue [8] . Ainsi tout élément de W2,2(I,E) admet un représentant continu et dont la dérivée admet aussi un représentant continu.
2. 3. Équation d'Euler-Lagrange
Article détaillé : Équation d'Euler-Lagrange.
La difficulté est maintenant d'exprimer le gradient des fonctions Φ et Ψ. L'équation d'Euler-Lagrange cherche dans un premier temps à trouver des fonctions de classe C2 qui minimisent Φ. L'espace vectoriel sous-jacent est celui des fonctions d'un intervalle borné et de classe C2 et nulles aux bornes de l'intervalle. Sur cet espace, le calcul du gradient de Φ n'est guère complexe, il donne aussi une idée de la solution ainsi que de la méthode pour y parvenir. En revanche, ce calcul est insuffisant dans le cas présent. Avec le bon produit scalaire, l'espace des fonctions de classe C2 n'est pas complet, ce qui empêche de disposer de la bonne géométrie permettant de démontrer la méthode du multiplicateur de Lagrange.
L'objectif est de généraliser un peu la démonstration pour permettre de disposer de l'égalité du gradient dans l'espace completW2,2(I,E). Dans un premier temps, exprimons l'égalité qui définit la différentielle de Φ en un point x, qui représente une fonction deW2,2(I,E) :
L'application DΦx est une application linéaire continue de W2,2(I,E) dans R, c'est-à-dire un élément du dual topologique de W2,2(I,E), que le produit scalaire permet d'identifier à W2,2(I,E). L'égalité précédente devient :
Autrement dit, le gradient de Φ au point x est une fonction de L2(I,E) dans R. De fait, ce gradient s'exprime à l'aide de l'équation d'Euler-Lagrange :
-
- Le gradient de Φ au point x est la fonction de I dans E, définie par :
Si la fonction φ est en général choisie au sens usuel de la dérivation, la fonction x(t) est une fonction de W2,2(I,E). Le symbole d/dtdoit être pris au sens de la dérivée d'une distribution, qui n'est ici nécessairement une fonction de carrée intégrable, définie presque partout.
Pour Ψ, la logique est absolument identique, mais cette fois-ci, la fonction est à valeurs dans F. En conséquence, la dérivée partielle de ψ par rapport à sa deuxième ou troisième variable n'est plus une application linéaire de E dans R, mais une application linéaire deE dans F. Ainsi, la différentielle de Ψ au point, une fonction x de I dans E, est une application de I dans L(E,F) l'ensemble des applications linéaires de E dans F. La logique reste la même.
-
- La différentielle de Ψ au point x est la fonction de I dans L(E,F), définie par :
2. 4. Théorèmes
Ce paragraphe est très proche du précédent dans le cas de la dimension finie. Le problème à résoudre est de trouver le minimum suivant :
Théorème du multiplicateur de Lagrange — Si le point x0 est un extremum local de Φ dans l'ensemble G, alors le noyau de la différentielle de Ψ au point x0 est orthogonal au gradient de Φ en ce point.
On obtient les mêmes corollaire, que l'on peut écrire :
Corollaire — Si le point x0 est un extremum local de Φ dans l'ensemble G et si la différentielle de Ψ au point x0 est surjective, alors il existe un vecteur λ0 de F tel que la fonction L de W2,2(I,E)xF dans R admet un gradient nul en (x0, λ0) :
Cette équation s'écrit encore :
Le signe d/dt doit être pris au sens de la dérivée des distributions. On obtient une solution faible, c'est-à-dire une fonction x définie presque partout et dérivable dans un sens faible. En revanche, si une fonction x de classe C2 est solution du problème de minimisation, comme ses dérivées premières et secondes sont des représentants de ses dérivées au sens faible, L'équation précédente est encore vérifiée.
2. 5. Application : Théorème isopérimétrique
Article détaillé : Théorème isopérimétrique.

On recherche la surface de plus grande aire, ayant une frontière de longueur égale à 2π. On remarque que la surface est nécessairement convexe, d'intérieur non vide. On considère une droite coupant la surface en deux. Cette droite est utilisée comme axe d'un repère orthonormal, dont les abscisses sont notées par la lettre t et les ordonnées par x. La frontière supérieure est paramétrable en une courbe x(t) et, si le repère est bien choisi, on peut prendre comme abscisse minimale -a et maximale a. On recherche alors une courbe x, définie entre -a et a tel que l'aire A soit maximale :
On sait de plus que la demi longueur de la frontière est égale à π :
La recherche de la surface se traite aussi avec le multiplicateur de Lagrange. La même astuce que celle utilisée dans l'exemple introductif montre, avec les notations usuelles :
On en déduit l'existence de valeurs λ et k tel que :
En notant u = x - k, on obtient :
On trouve l'équation d'un demi-cercle de rayon λ, la valeur λ est égale à 1 et k à 0. [9]
3. Voir aussi
3. 1. Notes
- Ce résultat est énoncé sous une forme équivalente mais moins générale dans : D. Hoareau Cauchy-Schwarz par le calcul différentiel MégaMaths sur ifrance (2003)
- On trouve ce corollaire dans : D. Klein Lagrange Multipliers without Permanent Scarring University of California at Berkeley
- Voir par exemple : M. Bierlaire (2006) "Introduction à l'optimisation différentiable", Presses Polytechniques et Universitaires Romandes, Ecole polytechnique fédérale de Lausanne
- Elle est explicitée dans l'article : D. Hoareau Cauchy-Schwarz par le calcul différentiel MégaMaths sur ifrance (2003)
- Cet exemple est extrait de : X. Gourdon Analyse, Les maths en tête : Mathématiques pour MP* Ellipses Marketing 2ième édition (2008) (ISBN 2729837590)
- Cet exemple est traité dans : C Barreteau Calcul des variations Ecole supérieure de physique et de chimie industrielle
- Pour plus de détails voir : L Andry Les espaces de Sobolev Ecole polytechnique fédérale de Lausanne
- Théorème VIII.2 p 122 Haïm Brezis, Analyse fonctionnelle : théorie et applications [détail des éditions]
- Ce calcul est présenté, par exemple sur : S. Mehl Didon, Carthage, calcul des variations et multiplicateur de LagrangeChronomath.com
3. 2. Article connexe
3. 3. Liens externes
- (fr) D. Hoareau Cauchy-Schwarz par le calcul différentiel sur megamaths
- (fr) La méthode du Lagrangien École des Hautes Études Commerciales Montréal Québec (1999)
- (fr) Extrema liés - Multiplicateurs de Lagrange sur BibM@th
- (en) D. Klein Lagrange Multipliers without Permanent Scarring Université de Berkeley
3. 4. Références
- (fr) X. Gourdon Analyse, Les maths en tête : Mathématiques pour MP* Ellipses Marketing 2ième édition (2008) (ISBN 2729837590)
- (fr) Haïm Brezis, Analyse fonctionnelle : théorie et applications [détail des éditions]
- (en) W. P. Ziemer Weakly Differentiable Functions: Sobolev Spaces and Functions of Bounded Variation Springer (1989) (ISBN 0387970177)
20:25 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Multiplicateurs de Lagrange
Dans mathématique optimisation problèmes, la méthode de Multiplicateurs de Lagrange, appelé ensuite Joseph Louis Lagrange, est une méthode pour trouver extrema d'a fonction de plusieurs variables sujet à un ou plusieurs contraintes; c'est l'outil de base dans l'optimisation contrainte non-linéaire. Simplement mise, la technique peut déterminer où sur un ensemble particulier de points (tels qu'a cercle, sphère, ou avion) une fonction particulière est la plus petite (ou la plus grande). Plus formellement, les multiplicateurs de Lagrange calculent points stationnaires de la fonction contrainte. Par Le théorème de Fermat, les extrema se produisent à ces points, ou sur la frontière, ou aux points où la fonction n'est pas différentiable. Il réduit la conclusion points stationnaires d'une fonction contrainte dedans n variables avec k contraintes à trouver les points stationnaires d'une fonction sans contrainte dedans n+k variables. La méthode présente une nouvelle variable scalaire inconnue (appelée le multiplicateur de Lagrange) pour chaque contrainte, et définit une nouvelle fonction (appelée Lagrangien) en termes de fonction originale, contraintes, et multiplicateurs de Lagrange. Considérez un cas bidimensionnel. Supposez que nous avons une fonction f(X,y) nous souhaitons maximiser ou réduire au minimum sujet à la contrainte là où c est une constante. Nous pouvons visualiser découpes de f donné près pour différentes valeurs de dn, et la découpe de g donné près g(X,y) = c. Supposez que nous marchons suivant la ligne de découpe avec g = c. En général les lignes de découpe de f et g peut être distinct, ainsi traversant la ligne de découpe pour g = c a pu intersecter avec ou croiser les lignes de découpe de f. C'est équivalent à dire cela tout en se déplaçant suivant la ligne de découpe pour g = c la valeur de f peut changer. Seulement quand la ligne de découpe pour g = c lignes de découpe de contacts de f tangentiellement, nous n'augmentons pas ou ne diminuons pas la valeur de f qu'est, quand les lignes contact de découpe mais ne croisent pas. Ceci se produit exactement quand composant tangentiel du dérivé total disparaît : , qui est au contraint points stationnaires de f(qui incluent les extrema locaux contraints, supposer f est différentiable). Informatique, c'est quand le gradient de f est normal aux contraintes : quand pour une certaine grandeur scalaire λ. Notez que la constante λ est exigé parce que, quoique les directions des deux vecteurs de gradient soient égales, les importances des vecteurs de gradient sont pas égale le plus susceptible. Un exemple familier peut être obtenu à partir des cartes de temps, avec le leur lignes de découpe pour la température et la pression : les extrema contraints se produiront où les cartes superposées montrent les lignes émouvantes (lignes isoplèthes). Géométriquement nous traduisons l'état de tangence à dire cela gradients de f et g sont les vecteurs parallèles au maximum, puisque les gradients sont toujours normaux aux lignes de découpe. Ainsi nous voulons des points (X,y) là où , et, de plus,g(X,y) = c. Pour incorporer ces deux conditions à une équation, nous présentons une grandeur scalaire inconnue, λ, et résolvez avec et Comme discuté ci-dessus, nous recherchons les points stationnaires de f vu tout en voyageant sur l'ensemble de niveau g(X,y) = c. Ceci se produit au moment même où le gradient de f n'a aucun composant tangentiel aux ensembles de niveau de g. Cette condition est équivalente à pour certains λ. Points stationnaires (X,y, λ) de F satisfaites également g(X,y) = c comme peut être vu en considérant le dérivé en ce qui concerne λ. Rendez-vous compte que les solutions sont points stationnaires du lagrangien F, et soyez points de selle: ils ne sont pas nécessairement extrema de F. F est illimité : donné un point (X,y) cela ne se trouve pas sur la contrainte, laissant marques Farbitrairement grand ou petit. Cependant, dans certaines prétentions plus fortes, car nous verrons au-dessous de, principe lagrangien fort se tient, dont déclare que les maximum f maximisez le lagrangien globalement. Dénotez la fonction objective près et laissez les contraintes soit donné près , peut-être par des constantes en mouvement vers la gauche, en tant que dedans . Le domaine de f devrait être un ensemble ouvert contenant tous les points satisfaisant les contraintes. En outre, f et gk doit avoir les premiers dérivés partiels continus et les gradients du gk nécessité ne pas être zéro sur le domaine.[1]Maintenant, définissez le lagrangien, Λ, As Observez que les critères et des contraintes d'optimisation gk(X) sont de manière compacte codés en tant que points stationnaires du lagrangien : et Collectivement, les points stationnaires du lagrangien, donnez un certain nombre d'équations uniques se montant à la longueur de plus la longueur de . Ceci souvent marques il possible de résoudre pour le chaque X et λk, sans inverser gk.[1] Pour cette raison, la méthode de multiplicateur de Lagrange peut être utile dans les situations où il est plus facile de trouver des dérivés des fonctions de contrainte que pour les inverser. Souvent les multiplicateurs de Lagrange ont une interprétation en tant que certaine quantité saillante d'intérêt. Pour voir pourquoi ceci pourrait être le cas, observez cela : Ainsi, λk est le taux de changement de la quantité étant optimisée en fonction de la variable de contrainte. Comme exemples, dedans Mécanique lagrangienne les équations du mouvement sont dérivées en trouvant les points stationnaires du action, l'intégrale de temps de la différence entre l'énergie cinétique et potentielle. Ainsi, la force sur une particule due à un potentiel scalaire, , peut être interprété comme multiplicateur de Lagrange déterminant le changement de l'action (transfert de potentiel à l'énergie cinétique) suivant une variation de la trajectoire contrainte des particules. Dans les sciences économiques, le bénéfice optimal à un joueur est calculé sujet à un espace contraint des actions, où un multiplicateur de Lagrange est la valeur de détendre une contrainte donnée (par exemple. par le corruption ou d'autres moyens). La méthode de multiplicateurs de Lagrange est généralisée par États de Karush-Kuhn-Tucker. Supposez-toi souhaiter maximiser f(X,y) = X + y sujet à la contrainte X2 + y2 = 1. La contrainte est le cercle d'unité, et ensembles de niveau de f sont les lignes diagonales (avec pente -1), ainsi on peut voir graphiquement que le maximum se produit à (et le minimum se produit à Formellement, ensemble g(X,y) = X2 + y2 − 1, et Placez le dérivé dΛ = 0, qui rapporte le système des équations : En tant que toujours, l'équation est la contrainte originale. Combinaison des deux premiers rendements d'équations X = y (explicitement, (autrement (i) rapporte 1 = 0), ainsi un peut résoudre pour λ, rapportant λ = − 1/(2X), dans lequel on peut substituer (ii)). La substitution dans (iii) rapporte 2X2 = 1, ainsi et les points stationnaires sont et . Évaluation de la fonction objective f sur ces rendements ainsi le maximum est , au lequel est atteint et le minimum est , au lequel est atteint . Supposez que vous voulez trouver les valeurs maximum pour dans la condition qui X et y les coordonnées se trouvent sur le cercle autour de l'origine avec le rayon √3, c'est-à-dire, Car il y a juste un état simple, nous emploierons seulement un multiplicateur, disons le λ. Employez la contrainte pour définir une fonction g(X, y): La fonction g est identiquement zéro sur le cercle du rayon √3. Tellement tout multiple de g(X, y) peut être ajouté à f(X, y) partantf(X, y) sans changement dans la région d'intérêt (au-dessus du cercle où notre contrainte originale est satisfaite). Laissé Les valeurs critiques de Λ produisez-vous quand son gradient est zéro. Les dérivés partiels sont L'équation (iii) est juste la contrainte originale. L'équation (i) implique X = 0 ou λ = −y. Dans le premier cas, si X = 0 alors nous devons avoir par (iii) et puis par (ii) λ=0. Dans le deuxième cas, si λ = −y et substituant dans l'équation (ii) nous avons cela, Puis X2 = 2y2. Substitution dans l'équation (iii) et solution pour y donne cette valeur de y: Ainsi il y a six points critiques : Évaluant l'objectif à ces points, nous trouvons Par conséquent, la fonction objective atteint a maximum global (en ce qui concerne les contraintes) à et a minimum global à Le point est a minimum local et est a maximum local. Supposez que nous souhaitons trouver le discret distribution de probabilité avec maximal entropie de l'information. Puis Naturellement, la somme de ces probabilités égale 1, ainsi notre contrainte est g(p) = 1 avec Nous pouvons employer des multiplicateurs de Lagrange pour trouver le point de l'entropie maximum (selon les probabilités). Pour tous k de 1 à n, nous avons besoin de cela ce qui donne Mise en oeuvre de la différentiation de ces derniers n des équations, nous obtenons Ceci montre cela tout pi soyez égal (parce qu'ils dépendent du λ seulement). En employant le ∑ de contraintek pk = 1, nous trouvons Par conséquent, la distribution uniforme est la distribution avec la plus grande entropie. L'optimisation contrainte joue un rôle central dedans sciences économiques. Par exemple, le problème bien choisi pour aconsommateur est représenté en tant qu'un d'a de maximum fonction de service sujet à a contrainte de budget. Le multiplicateur de Lagrange a une interprétation économique en tant que prix virtuel lié à la contrainte, dans ce cas-ci utilité marginale de revenu. A donné optimisation convexe problème sous le format standard avec le domaine avoir l'intérieur non vide, Fonction lagrangienne est défini As Les vecteurs λ et ν s'appellent variables duelles ou Vecteurs de multiplicateur de Lagrange lié au problème. Lagrange à 2 modes de fonctionnement est défini As L'à 2 modes de fonctionnement g est concave, même lorsque le problème initial n'est pas convexe. Les limites inférieures de rendements à 2 modes de fonctionnement sur la valeur optimale p * du problème initial ; pour quels et quels ν nous avons . Si une qualification de contrainte telle que l'état du couvreur se tient et le problème original est convexe, alors nous avons la dualité forte, c.-à-d. . Pour des références au travail original de Lagrange et pour un compte de la terminologie voyez l'entrée de multiplicateur de Lagrange dedans Exposition Pour le texte additionnel et les applet interactifs Source : http://www.worldlingo.com/ma/enwiki/fr/Lagrange_multipliersMultiplicateurs de Lagrange
Introduction
Justification
Avertissement : extrema contre les points stationnaires
Une formulation plus générale : Le principe lagrangien faible
Interprétation de λi
Exemples
Exemple très simple
Exemple simple
Exemple : entropie
Sciences économiques
Le principe lagrangien fort : Dualité de Lagrange
Voyez également
Références
Liens externes
Table des matières |
20:23 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
Multiplicateur de Lagrange
Le multiplicateur de Lagrange est une méthode permettant de trouver des points stationnaires (maximum, minimum...) d'une fonction dérivable d'une ou plusieurs variables. Cette technique est utile entre autres pour résoudre les problèmes d'optimisation sous contrainte(s) (linéaire(s)). Supposons que le problème soit de trouver un extremum d'une fonction de N variables, tout en imposant K contraintes sur les valeurs de celle-ci. La méthode consiste à introduire une inconnue scalaire supplémentaire - appelée multiplicateur de Lagrange - par contrainte; il y a donc K multiplicateurs. On forme ensuite une combinaison linéaire de la fonction et des contraintes, où les coefficients des contraintes sont les multiplicateurs de Lagrange. Le problème passe ainsi d'un problème d'optimisation avec contrainte à un problème non contraint, qui peut être résolu par une méthode adaptée (gradient conjugué, par exemple). Hugh Everett a généralisé la méthode aux fonctions non-dérivables, sous réserve de disposer d'un algorithme déterminant l'optimum (ou les optima) d'une fonction sans contrainte (dans la pratique, on doit se contenter d'heuristiques). Soit le problème d'optimisation : soumis à des contraintes d'égalité Si le nombre m de contraintes est supérieur au nombre n de variables, le problème est surcontraint et n'admet en général pas de solution. La méthode des multiplicateurs de Lagrange stipule qu'on atteint la valeur optimale de F(X) pour les valeurs xi de X qui satisfont le système : Cette méthode peut être généralisée aux problèmes d'optimisation incluant des contraintes d'inégalités (ou non linéaires) en utilisant les conditions de Kuhn-Tucker. Mais également sur des fonctions discrètes à maximiser ou minimiser sous contraintes, moyennant un changement d'interprétation, en utilisant la méthode des multiplicateurs d'Everett (ou de Lagrange généralisés), plus volontiers appelée méthode des pénalités. Supposons que l'on veuille déterminer le rayon R et la hauteur H d'un cylindre qui minimise la surface S de celui-ci, tout en ayant un volume V imposé. Le problème s'écrit sous la forme : Minimiser sous Ayant une seule contrainte, on ajoute un seul multiplicateur de Lagrange : Le problème revient maintenant à minimiser le Lagrangien On cherche donc à annuler le Gradient du Lagrangien, soit : ce qui nous amène au système : L'équation (2) nous donne : L'équation (1) nous donne : L'équation (3) nous donne enfin : Si le volume imposé est V = 1m3, l'optimum de la fonction S est : Et la fonction vaut Source : http://www.techno-science.net/?onglet=glossaire&defin...Écriture du problème
 où
où 


Exemple




 ,
,


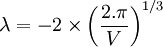

 en ce point.
en ce point.
20:22 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook
13/02/2011
Mathématique du crime Guillermo Martinez, Eduardo Jimenez Roman (broché). Paru en 09/2004 Livre

 |
|
09:06 | Lien permanent | Commentaires (0) | | del.icio.us | | Digg | Facebook